
DuckDB Sort实现调查
关于DuckDB V1.4.0的Sort实现的详解,可以看DuckDB于9月26日发的新Blog
目前DuckDB两个版本的Sort均是由Laurens Kuiper(Software Developer at DuckDB Labs and Ph.D. Student in the Database Architectures group at CWI.)写的
因此DuckDB的Sort分为两个文件夹
在src/common目录下,有sort和sorting文件夹
v1.4.0的排序方法位于sorting目录下(具体方法则位于third_party/ska_sort,third_party/verge_sort,third_party/pdq_sort下面),对应的状态管理是
class SortLocalSinkState;class SortGlobalSinkState;class SortLocalSourceState;class SortGlobalSourceState;而v1.4.0之前的排序方法位于sort目录下,对应的状态管理是
struct GlobalSortStatestruct LocalSortState调研主要以TPC-H Q1为主,结合Debug版本的编译与GDB,观察程序的实际执行路径
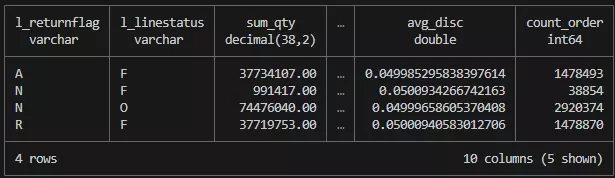
SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_orderFROM lineitemWHERE l_shipdate <= CAST('1998-09-02' AS date)GROUP BY l_returnflag, l_linestatusORDER BY l_returnflag, l_linestatus;最后结果的Aggregate分成4组,结果应该是下面情况
在PhysicalPlanGenerator::CreatePlan中,会将逻辑计划中的OrderBy转为物理计划,我们GDB从这里开始切入
case LogicalOperatorType::LOGICAL_ORDER_BY: return CreatePlan(op.Cast<LogicalOrder>());前置知识
Key与Payload
Key为排序键(参与排序的数据),Payload则是不参与排序的数据
- 分离存储:key数据和payload数据分别存储在不同的集合中
- 指针关联:通过在排序键中存储payload的指针来建立关联
- 类型特化:针对不同的排序键类型(固定16字节、24字节、32字节、变长32字节等)进行优化
- 延迟绑定:在数据追加时立即建立key-payload关联,为后续排序做准备
如果是存在多个列需要Sort,就会把多列的数据组合为一行数据,这样排序只需要做一次(就是以行为单位做Sort)
DuckDB v1.4.0的做法
定义了新的枚举类SortKetyType
enum class SortKeyType : uint8_t { INVALID = 0, //! Without payload NO_PAYLOAD_FIXED_8 = 1, NO_PAYLOAD_FIXED_16 = 2, NO_PAYLOAD_FIXED_24 = 3, NO_PAYLOAD_FIXED_32 = 4, NO_PAYLOAD_VARIABLE_32 = 5, //! With payload (requires row pointer in key) PAYLOAD_FIXED_16 = 6, PAYLOAD_FIXED_24 = 7, PAYLOAD_FIXED_32 = 8, PAYLOAD_VARIABLE_32 = 9,};sort.cpp
Sort的运行函数如下:
对于orders,这是一个std::vector
运行Q1时orders.size()为2,与order by的列数一致
如果进一步检查其中的expressions,可以发现是l_returnflag和l_linestatus
orders.GetOrderModifieer()获取ASC和DESC
order.expression->return_type获取列的类型
将以上信息传入create_children,作为构成Key组合键的信息
通过binder.BindScalarFunction(DEFAULT_SCHEMA, "create_sort_key", std::move(create_children), error)生成reate_sort_key——对于Q1,进入LogicalTypeId::BIGINT分支
同时紧跟在这段代码后面,生成decode_sort_key
decode_sort_key->return_type = LogicalType::STRUCT(std::move(decode_child_list));根据projection_map生成payload_layout(这是一种行存形式tupleDataLayout)和填充output_projection_columns
vector<LogicalType> payload_types; for (idx_t output_col_idx = 0; output_col_idx < projection_map.size(); output_col_idx++) { const auto &input_col_idx = projection_map[output_col_idx]; const auto it = input_column_to_key.find(input_col_idx); if (it != input_column_to_key.end()) { // Projected column also appears as a key, just reference it output_projection_columns.push_back({false, it->second, output_col_idx}); } else { // Projected column does not appear as a key, add to payload layout output_projection_columns.push_back({true, payload_types.size(), output_col_idx}); payload_types.push_back(input_types[input_col_idx]); input_projection_map.push_back(input_col_idx); } } payload_layout->Initialize(payload_types, TupleDataValidityType::CAN_HAVE_NULL_VALUES);然后用std::sort对于输出用的project_column进行排序,将Key的那部分移动到vector的开头
std::sort(output_projection_columns.begin(), output_projection_columns.end(), [](const SortProjectionColumn &lhs, const SortProjectionColumn &rhs) { if (lhs.is_payload == rhs.is_payload) { return lhs.layout_col_idx < rhs.layout_col_idx; } return lhs.is_payload < rhs.is_payload; });完整代码如下
Sort::Sort(ClientContext &context, const vector<BoundOrderByNode> &orders, const vector<LogicalType> &input_types, vector<idx_t> projection_map, bool is_index_sort_p) : key_layout(make_shared_ptr<TupleDataLayout>()), payload_layout(make_shared_ptr<TupleDataLayout>()), is_index_sort(is_index_sort_p) { // Convert orders to a single "create_sort_key" expression (and corresponding "decode_sort_key") FunctionBinder binder(context); vector<unique_ptr<Expression>> create_children; vector<unique_ptr<Expression>> decode_children; child_list_t<LogicalType> decode_child_list; for (idx_t col_idx = 0; col_idx < orders.size(); col_idx++) { const auto &order = orders[col_idx];
// Create: for each column we have two arguments: 1. the column, 2. sort specifier create_children.emplace_back(order.expression->Copy()); create_children.emplace_back(make_uniq<BoundConstantExpression>(Value(order.GetOrderModifier())));
// Avoid having unnamed structs fields (otherwise we get a parser exception while binding) const auto col_name = StringUtil::Format("c%llu", col_idx); auto col_type = order.expression->return_type; decode_child_list.emplace_back(col_name, col_type); col_type = TypeVisitor::VisitReplace(col_type, [](const LogicalType &type) { if (type.id() != LogicalTypeId::STRUCT) { return type; } child_list_t<LogicalType> internal_child_list; for (const auto &child : StructType::GetChildTypes(type)) { internal_child_list.emplace_back(StringUtil::Format("c%llu", internal_child_list.size()), child.second); } return LogicalType::STRUCT(std::move(internal_child_list)); });
// Decode: for each column we have two arguments: 1. col name + type, 2. sort specifier decode_children.emplace_back(make_uniq<BoundConstantExpression>(Value(col_name + " " + col_type.ToString()))); decode_children.emplace_back(make_uniq<BoundConstantExpression>(order.GetOrderModifier())); }
ErrorData error; create_sort_key = binder.BindScalarFunction(DEFAULT_SCHEMA, "create_sort_key", std::move(create_children), error); if (!create_sort_key) { throw InternalException("Unable to bind create_sort_key in Sort::Sort"); }
switch (create_sort_key->return_type.id()) { case LogicalTypeId::BIGINT: decode_children.insert(decode_children.begin(), make_uniq<BoundReferenceExpression>(LogicalType::BIGINT, static_cast<storage_t>(0))); break; default: D_ASSERT(create_sort_key->return_type.id() == LogicalTypeId::BLOB); decode_children.insert(decode_children.begin(), make_uniq<BoundReferenceExpression>(LogicalType::BLOB, static_cast<storage_t>(0))); }
decode_sort_key = binder.BindScalarFunction(DecodeSortKeyFun::GetFunction(), std::move(decode_children)); if (!decode_sort_key) { throw InternalException("Unable to bind decode_sort_key in Sort::Sort"); }
// A bit hacky, but this way we make sure that the output does contain the unnamed structs again decode_sort_key->return_type = LogicalType::STRUCT(std::move(decode_child_list));
// For convenience, we fill the projection map if it is empty if (projection_map.empty()) { projection_map.reserve(input_types.size()); for (idx_t col_idx = 0; col_idx < input_types.size(); col_idx++) { projection_map.push_back(col_idx); } }
// We need to output this many columns, reserve output_projection_columns.reserve(projection_map.size());
// Create mapping from input column to key (so we won't duplicate columns in key/payload) unordered_map<idx_t, idx_t> input_column_to_key; for (idx_t key_idx = 0; key_idx < orders.size(); key_idx++) { const auto &key_order_expr = *orders[key_idx].expression; if (key_order_expr.GetExpressionClass() == ExpressionClass::BOUND_REF) { input_column_to_key.emplace(key_order_expr.Cast<BoundReferenceExpression>().index, key_idx); } }
// Construct payload layout (excluding columns that also appear as key) vector<LogicalType> payload_types; for (idx_t output_col_idx = 0; output_col_idx < projection_map.size(); output_col_idx++) { const auto &input_col_idx = projection_map[output_col_idx]; const auto it = input_column_to_key.find(input_col_idx); if (it != input_column_to_key.end()) { // Projected column also appears as a key, just reference it output_projection_columns.push_back({false, it->second, output_col_idx}); } else { // Projected column does not appear as a key, add to payload layout output_projection_columns.push_back({true, payload_types.size(), output_col_idx}); payload_types.push_back(input_types[input_col_idx]); input_projection_map.push_back(input_col_idx); } } payload_layout->Initialize(payload_types, TupleDataValidityType::CAN_HAVE_NULL_VALUES);
// Sort the output projection columns so we're gathering the columns in order std::sort(output_projection_columns.begin(), output_projection_columns.end(), [](const SortProjectionColumn &lhs, const SortProjectionColumn &rhs) { if (lhs.is_payload == rhs.is_payload) { return lhs.layout_col_idx < rhs.layout_col_idx; } return lhs.is_payload < rhs.is_payload; });
// Finally, initialize the key layout (now that we know whether we have a payload) key_layout->Initialize(orders, create_sort_key->return_type, !payload_types.empty());}最后单独生成key_layout
key_layout->Initialize(orders, create_sort_key->return_type, !payload_types.empty());tuple_data_layout.cpp
根据参与排序键的属性,生成sort_width
对于Q1,这里的sort_width的最终结果为4(2+2),GetTypeIdSize(physical_type)得到的是1
if (TypeIsConstantSize(physical_type)) { // NULL byte + fixed-width type sort_width += 1 + GetTypeIdSize(physical_type);} else if (logical_type == LogicalType::VARCHAR && order.stats && StringStats::HasMaxStringLength(*order.stats)) { // NULL byte + maximum string length + string delimiter sort_width += 1 + StringStats::MaxStringLength(*order.stats) + 1;} else { // We don't know how long the key will be sort_width = DConstants::INVALID_INDEX; break;}根据row_width选择SortKetyType,对于Q1,因为LogicalType是LogicalTypeId::BIGINT,所以初始值为8,因为有Payload所以再加8,最后sort_width 是16,由于有Payload,选择SortKeyType::PAYLOAD_FIXED_16
idx_t temp_row_width = type.id() == LogicalTypeId::BIGINT ? 8 : sort_width; if (sort_width != DConstants::INVALID_INDEX && has_payload) { temp_row_width += 8; } if (temp_row_width <= 8) { D_ASSERT(!has_payload); row_width = 8; sort_key_type = SortKeyType::NO_PAYLOAD_FIXED_8; } else if (temp_row_width <= 16) { row_width = 16; sort_key_type = has_payload ? SortKeyType::PAYLOAD_FIXED_16 : SortKeyType::NO_PAYLOAD_FIXED_16; } else if (temp_row_width <= 24) { row_width = 24; sort_key_type = has_payload ? SortKeyType::PAYLOAD_FIXED_24 : SortKeyType::NO_PAYLOAD_FIXED_24; } else if (temp_row_width <= 32) { row_width = 32; sort_key_type = has_payload ? SortKeyType::PAYLOAD_FIXED_32 : SortKeyType::NO_PAYLOAD_FIXED_32; } else { row_width = 32; sort_key_type = has_payload ? SortKeyType::PAYLOAD_VARIABLE_32 : SortKeyType::NO_PAYLOAD_VARIABLE_32;
// Variable-size sort key, also set these properties all_constant = false; heap_size_offset = has_payload ? SortKey<SortKeyType::PAYLOAD_VARIABLE_32>::HEAP_SIZE_OFFSET : SortKey<SortKeyType::NO_PAYLOAD_VARIABLE_32>::HEAP_SIZE_OFFSET; }sorted_run.cpp
在Sort算子的Sink阶段(可以理解为算子的执行与输出)如果有Payload,则需要给Payload设置相对应的Pointer
void SortedRun::Sink(DataChunk &key, DataChunk &payload) { D_ASSERT(!finalized); key_data->Append(key_append_state, key); if (payload_data) { D_ASSERT(key.size() == payload.size()); payload_data->Append(payload_append_state, payload); SetPayloadPointer(key_append_state.chunk_state.row_locations, payload_append_state.chunk_state.row_locations, key.size(), key_data->GetLayout().GetSortKeyType()); }}通过SetPayloadPointer设置相对应的指针,根据sort_key_type找到相对应的模板生成(对于Q1,这里的count为4)
static void SetPayloadPointer(Vector &key_locations, Vector &payload_locations, const idx_t count, const SortKeyType &sort_key_type) { switch (sort_key_type) { case SortKeyType::PAYLOAD_FIXED_16: return TemplatedSetPayloadPointer<SortKeyType::PAYLOAD_FIXED_16>(key_locations, payload_locations, count); case SortKeyType::PAYLOAD_FIXED_24: return TemplatedSetPayloadPointer<SortKeyType::PAYLOAD_FIXED_24>(key_locations, payload_locations, count); case SortKeyType::PAYLOAD_FIXED_32: return TemplatedSetPayloadPointer<SortKeyType::PAYLOAD_FIXED_32>(key_locations, payload_locations, count); case SortKeyType::PAYLOAD_VARIABLE_32: return TemplatedSetPayloadPointer<SortKeyType::PAYLOAD_VARIABLE_32>(key_locations, payload_locations, count); default: throw NotImplementedException("SetPayloadPointer for %s", EnumUtil::ToString(sort_key_type)); }}可以看到模板设置的是指针
template <SortKeyType SORT_KEY_TYPE>static void TemplatedSetPayloadPointer(Vector &key_locations, Vector &payload_locations, const idx_t count) { using SORT_KEY = SortKey<SORT_KEY_TYPE>;
const auto key_locations_ptr = FlatVector::GetData<SORT_KEY *>(key_locations); const auto payload_locations_ptr = FlatVector::GetData<data_ptr_t>(payload_locations);
for (idx_t i = 0; i < count; i++) { key_locations_ptr[i]->SetPayload(payload_locations_ptr[i]); }}SortSwitch判断KeyType类型,从模板转入对应Sort方法
static void SortSwitch(const TupleDataCollection &key_data, bool is_index_sort) { const auto sort_key_type = key_data.GetLayout().GetSortKeyType(); switch (sort_key_type) { case SortKeyType::NO_PAYLOAD_FIXED_8: return TemplatedSort<SortKeyType::NO_PAYLOAD_FIXED_8>(key_data, is_index_sort); case SortKeyType::NO_PAYLOAD_FIXED_16: return TemplatedSort<SortKeyType::NO_PAYLOAD_FIXED_16>(key_data, is_index_sort); case SortKeyType::NO_PAYLOAD_FIXED_24: return TemplatedSort<SortKeyType::NO_PAYLOAD_FIXED_24>(key_data, is_index_sort); case SortKeyType::NO_PAYLOAD_FIXED_32: return TemplatedSort<SortKeyType::NO_PAYLOAD_FIXED_32>(key_data, is_index_sort); case SortKeyType::NO_PAYLOAD_VARIABLE_32: return TemplatedSort<SortKeyType::NO_PAYLOAD_VARIABLE_32>(key_data, is_index_sort); case SortKeyType::PAYLOAD_FIXED_16: return TemplatedSort<SortKeyType::PAYLOAD_FIXED_16>(key_data, is_index_sort); case SortKeyType::PAYLOAD_FIXED_24: return TemplatedSort<SortKeyType::PAYLOAD_FIXED_24>(key_data, is_index_sort); case SortKeyType::PAYLOAD_FIXED_32: return TemplatedSort<SortKeyType::PAYLOAD_FIXED_32>(key_data, is_index_sort); case SortKeyType::PAYLOAD_VARIABLE_32: return TemplatedSort<SortKeyType::PAYLOAD_VARIABLE_32>(key_data, is_index_sort); default: throw NotImplementedException("TemplatedSort for %s", EnumUtil::ToString(sort_key_type)); }}在TemplatedSort当中,则默认使用vergesort,fallback时会选择ska_sort
const auto ska_sort_width = MinValue<idx_t>(layout.GetSortWidth(), sizeof(uint64_t));对于Q1,这里的ska_sort_width为4,为计算前面的sort_width所得到的
完整代码如下:
auto begin = BLOCK_ITERATOR(state, 0); auto end = BLOCK_ITERATOR(state, key_data.Count());
const auto requires_next_sort = is_index_sort ? false : !SORT_KEY::CONSTANT_SIZE || SORT_KEY::INLINE_LENGTH != sizeof(uint64_t); const auto ska_sort_width = MinValue<idx_t>(layout.GetSortWidth(), sizeof(uint64_t)); const auto &sort_skippable_bytes = layout.GetSortSkippableBytes(); auto ska_extract_key = SkaExtractKey<SORT_KEY>(requires_next_sort, ska_sort_width, sort_skippable_bytes, context.interrupted);
const auto fallback = [ska_extract_key](const BLOCK_ITERATOR &fb_begin, const BLOCK_ITERATOR &fb_end) { duckdb_ska_sort::ska_sort(fb_begin, fb_end, ska_extract_key); }; duckdb_vergesort::vergesort(begin, end, std::less<SORT_KEY>(), fallback);vergesort.h
对于verge_sort小于128个元素的数组,使用回退算法
而Q1需要排序的Aggregate分组只有4个(小于阈值24),所以直接fallback到ska_sort
if (dist < 128) { // Vergesort is inefficient for small collections fallback(first, last); return;}ska_sort.hpp
ska_sort内部则是inplace_radix_sort
template<typename It, typename ExtractKey>static void ska_sort(It begin, It end, ExtractKey && extract_key){ detail::inplace_radix_sort<128, 1024>(begin, end, extract_key);}对于Q1会掉入StdSortFallbacks,这里的fallback被设置成为了pdqsort_branchless,同时配置好comp函数
template<typename It, typename ExtractKey>inline void StdSortFallback(It begin, It end, ExtractKey & extract_key){ // LNK note that we use the full comparison (not just extracted key) here static const auto comp = [&](const typename std::remove_reference<decltype(*begin)>::type & l, const typename std::remove_reference<decltype(*begin)>::type & r){ return l < r; }; static const auto fallback = [&](const It &fb_begin, const It &fb_end) { duckdb_pdqsort::pdqsort_branchless(fb_begin, fb_end, comp); }; duckdb_vergesort::vergesort(begin, end, comp, fallback);}调用堆栈如下图
pdq_sort.h
Q1需要排序的Aggregate分组只有4个(小于阈值24),进入pdqsort_detail::pdqsort_loop
template<class Iter, class Compare>inline void pdqsort_branchless(Iter begin, Iter end, Compare comp) { if (begin == end) return; pdqsort_detail::pdqsort_loop<Iter, Compare, true>( begin, end, comp, pdqsort_detail::log2(end - begin));}由于再次小于阈值24,所以进入insertion_sort
if (size < insertion_sort_threshold) { if (leftmost) insertion_sort(begin, end, comp); else unguarded_insertion_sort(begin, end, comp); return;}C++
template<class Iter, class Compare> inline void insertion_sort(Iter begin, Iter end, Compare comp) { typedef typename std::iterator_traits<Iter>::value_type T; if (begin == end) return;
for (Iter cur = begin + 1; cur != end; ++cur) { Iter sift = cur; Iter sift_1 = cur - 1;
// Compare first so we can avoid 2 moves for an element already positioned correctly. if (comp(*sift, *sift_1)) { T tmp = PDQSORT_PREFER_MOVE(*sift);
do { *sift-- = PDQSORT_PREFER_MOVE(*sift_1); } while (sift != begin && comp(tmp, *--sift_1));
*sift = PDQSORT_PREFER_MOVE(tmp); } } }DuckDB v1.4.0之前
我调试使用的是v1.3.2版本
状态管理默认的进入入口会是LocalSortState::SortInMemory()
对于这个版本,Sort会直接调用src/common/sort/radix_sort.cpp中的RadixSort
有意思的地方在于,虽然l_returnflag和l_linestatus是varchar,但contains_string这里值为false——实际调试显示l_returnflag和varchar被优化为Uint8
以及,虽然函数的名称为RadixSort,但也会根据排序组数选择不同算法
同样因为只有4组,小于阈值24,所以还是InsertationSort——但这个应该是Laurens Kuiper参考原版的PDQSort自己写的
if (count <= SortConstants::INSERTION_SORT_THRESHOLD) { return InsertionSort(dataptr, nullptr, count, col_offset, sort_layout.entry_size, sorting_size, 0, false); }InsertationSort内部
inline void InsertionSort(const data_ptr_t orig_ptr, const data_ptr_t temp_ptr, const idx_t &count, const idx_t &col_offset, const idx_t &row_width, const idx_t &total_comp_width, const idx_t &offset, bool swap) { const data_ptr_t source_ptr = swap ? temp_ptr : orig_ptr; const data_ptr_t target_ptr = swap ? orig_ptr : temp_ptr; if (count > 1) { const idx_t total_offset = col_offset + offset; auto temp_val = make_unsafe_uniq_array_uninitialized<data_t>(row_width); const data_ptr_t val = temp_val.get(); const auto comp_width = total_comp_width - offset; for (idx_t i = 1; i < count; i++) { FastMemcpy(val, source_ptr + i * row_width, row_width); idx_t j = i; while (j > 0 && FastMemcmp(source_ptr + (j - 1) * row_width + total_offset, val + total_offset, comp_width) > 0) { FastMemcpy(source_ptr + j * row_width, source_ptr + (j - 1) * row_width, row_width); j--; } FastMemcpy(source_ptr + j * row_width, val, row_width); } } if (swap) { memcpy(target_ptr, source_ptr, count * row_width); }}DuckDB版RadixSort完整代码如下
void RadixSort(BufferManager &buffer_manager, const data_ptr_t &dataptr, const idx_t &count, const idx_t &col_offset, const idx_t &sorting_size, const SortLayout &sort_layout, bool contains_string) {
if (contains_string) { auto begin = duckdb_pdqsort::PDQIterator(dataptr, sort_layout.entry_size); auto end = begin + count; duckdb_pdqsort::PDQConstants constants(sort_layout.entry_size, col_offset, sorting_size, *end); return duckdb_pdqsort::pdqsort_branchless(begin, begin + count, constants); }
if (count <= SortConstants::INSERTION_SORT_THRESHOLD) { return InsertionSort(dataptr, nullptr, count, col_offset, sort_layout.entry_size, sorting_size, 0, false); }
if (sorting_size <= SortConstants::MSD_RADIX_SORT_SIZE_THRESHOLD) { return RadixSortLSD(buffer_manager, dataptr, count, col_offset, sort_layout.entry_size, sorting_size); }
const auto block_size = buffer_manager.GetBlockSize(); auto temp_block = buffer_manager.Allocate(MemoryTag::ORDER_BY, MaxValue(count * sort_layout.entry_size, block_size)); auto pre_allocated_array = make_unsafe_uniq_array_uninitialized<idx_t>(sorting_size * SortConstants::MSD_RADIX_LOCATIONS); RadixSortMSD(dataptr, temp_block.Ptr(), count, col_offset, sort_layout.entry_size, sorting_size, 0, pre_allocated_array.get(), false);}性能对比参照
这是DuckDB关于他们最新Sort的Pull Request解释,该版本用于最新的DuckDB V1.4.0中的order by——他们在PR中说明将会替换原有排序方式,并且在测试中有2倍以上的性能提升
| Table | Column Type(s) | Rows [Millions] | Current [s] | New [s] | Speedup [x] |
|---|---|---|---|---|---|
| Ascending | 1 UBIGINT | 10 | 0.110 | 0.033 | 3.333 |
| Ascending | 1 UBIGINT | 100 | 0.912 | 0.181 | 5.038 |
| Ascending | 1 UBIGINT | 1000 | 15.302 | 1.475 | 10.374 |
| Descending | 1 UBIGINT | 10 | 0.121 | 0.034 | 3.558 |
| Descending | 1 UBIGINT | 100 | 0.908 | 0.207 | 4.386 |
| Descending | 1 UBIGINT | 1000 | 15.789 | 1.712 | 9.222 |
| Random | 1 UBIGINT | 10 | 0.120 | 0.094 | 1.276 |
| Random | 1 UBIGINT | 100 | 1.028 | 0.587 | 1.751 |
| Random | 1 UBIGINT | 1000 | 17.554 | 6.493 | 2.703 |
| TPC-H SF1 l_comment | 1 VARCHAR | ~6 | 0.848 | 0.296 | 2.864 |
| TPC-H SF 10 l_comment | 1 VARCHAR | ~60 | 8.465 | 3.090 | 2.739 |
| TPC-H SF 100 l_comment | 1 VARCHAR | ~600 | 300+ | 35.187 | 8.525+ |
| TPC-H SF 1 lineitem by l_shipdate | 15 Mixed | ~6 | 0.328 | 0.189 | 1.735 |
| TPC-H SF 10 lineitem by l_shipdate | 15 Mixed | ~60 | 3.353 | 1.520 | 2.205 |
| TPC-H SF 100 lineitem by l_shipdate | 15 Mixed | ~600 | 273.982 | 80.919 | 3.385 |
参考资料
第一个是DuckDB的官方博客,2和3是知乎上的分析,4是关于DuckDB Sort方法的论文(可以看到核心是PDQSort和RadixSort)——这些分析针对的是v1.4.0之前的情况
预计2025年9-10月DuckDB社区会有Blog说明v1.4.0的Sort的情况
Fastest Table Sort in the West – Redesigning DuckDB’s Sort
2021年Laurens Kuiper做的Sort重构:Rework physical ORDER BY
AI辅助解释
TupleDataLayout
TupleDataLayout 类详细解释
TupleDataLayout是 DuckDB 中用于管理行数据布局的核心类,它定义了如何在内存中组织和存储元组(行)数据。核心功能
1. 数据组织结构
TupleDataLayout管理行数据的内存布局,包含以下组件:
- 有效性标志区域 (
flag_width): 存储NULL值标记- 数据区域 (
data_width): 存储实际列数据- 聚合状态区域 (
aggr_width): 存储聚合函数状态- 排序键区域 (
sort_width): 存储排序相关数据2. 主要特性
类型管理
- 支持多种数据类型的列
- 管理聚合函数对象
- 提供类型安全的访问接口
嵌套结构支持
- 支持结构体类型的递归布局
- 每个结构体列都有自己的
TupleDataLayout内存优化
- 区分定长和变长列以优化内存使用
- 支持堆内存管理用于变长数据
初始化方法
1. 完整初始化
2. 仅类型初始化
3. 仅聚合初始化
4. 排序布局初始化
访问器方法
基本信息获取
ColumnCount(): 返回列数量AggregateCount(): 返回聚合函数数量GetTypes(): 获取列类型列表GetAggregates(): 获取聚合函数列表布局信息
GetRowWidth(): 整行宽度(包含填充)GetDataOffset(): 数据区域起始偏移GetDataWidth(): 数据区域宽度GetAggrOffset(): 聚合区域起始偏移GetAggrWidth(): 聚合区域宽度GetOffsets(): 各列在行中的偏移特殊属性检查
AllConstant(): 检查是否所有列都是定长AllValid(): 检查是否所有列都不含NULL值HasDestructor(): 检查聚合函数是否有析构器IsSortKeyLayout(): 检查是否为排序键布局排序支持
- 支持不同类型的排序键
- 提供排序优化,包括可跳过的字节
GetSortWidth()和GetSortSkippableBytes()用于排序性能优化内存管理特性
有效性管理
支持不同的NULL值处理策略:
- 完全不允许NULL值
- 支持NULL值标记
资源清理
- 跟踪需要析构的聚合函数索引
- 确保资源正确释放
使用场景
- 查询执行: 在各种算子中管理行数据布局
- 聚合操作: 存储和管理聚合函数状态
- 排序操作: 优化排序键的内存布局
- 数据交换: 在不同算子间传递结构化数据
- 内存优化: 最小化内存占用和缓存未命中
TupleDataLayout是 DuckDB 高性能查询执行的关键组件,通过精确控制数据在内存中的布局来提升查询性能。
结语
对于Q1而言,DuckDB使用的Sort的本质用的还是插入排序InsertationSort
其速度提升主要来源于流程的优化——正如PR里所说的从ROwDataCollection转为了使用延迟指针(lazy pointer)TupleDataCollection,减轻数据溢出,降低合并成本