
生产实习记录
生产实习记录
2023年6月学校安排去中软国际下属的一家公司进行生产实习。
个人觉得这次实习还是蛮有意思的:一个Hadoop开发项目。但首先于时间和参与项目的队友编程能力,在一点遗憾中结束了这次生产实习。
现在记录下当时的踩坑记录
Hadoop学习
在Windows下配置Hadoop环境的注意事项
将C:\PROGRA~1\Java\jdk1.7.0_67 改为 D:\Softwares\jdk1.8(在环境变量设置中JAVA_HOME的值)(如果路径中有“Program Files”,则将Program Files改为 PROGRA~1)看完教程后嫌麻烦,还是VMware装三台CentOS 7虚拟机完成Hadoop集群搭建。
搭建完成后,使用jps命令查看运行情况
Idea Hadoop配置
Windows:IDEA配置Maven、Hadoop详细教程
hadoop namenode -formatexport HADOOP_HOME=/root/hadoop-2.10.2export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinHDFS指令
hadoop fs -ls /test等价于
hadoop fs -ls hdfs:///testhadoop fs -mkdir直接访问本机文件系统
hadoop fs -ls file:///root下面的操作基本就和Linux的Shell命令差不多,CSDN和博客园哪些那些记录的更加详细
hadoop fs -mkdirhadoop fs -touchzhadoop fs -cathadoop fs -cp file:///root/1.txt /test/hadoop fs -mv file:///root/1.txt /test/hadoop fs -rmhadoop fs -putshadoop fs -appendToFile <local> <remote>hadoop fs -put /root/1.txt hdfs:///test/2.txthadoop fs -get hdfs:///test/2.txt files:///root/MapReduce基本概念
map:分开计算
shuffle:将map结果分组,排序整理
reduce:统计
shuffle = map.shuffle + reduce.shuffle
reduce的shuffle不需要编程
MapReduce操作
数据类型
数字型
框架需要对key和value的类(classes)进行序列化操作,因此,这些类需要实现Writable接口。
另外,为了方便框架执行排序操作,key类必须实现WritableComparable接口。Hadoop定义的数字类型有BooleanWritable,ByteWritable, IntWritable, LongWritable,FloatWritable,DoubleWritable 分别对应:boolean,byte,int, long, float, double 基本类型。这些类中,都有一个get()方法得到基础类型的值,它们的构造器参数可以是其对应的基础类型的值。如:
IntWritable value = new IntWritable(123);int data = value.get();字符型
Text 是Hadoop定义的字符类型,对应 String。如:
Text value = new Text("abc"); //创建Text类型数据String str = value.toString(); //将Text类型数据转换为StringExample
需要一个Mapper和Reducer
Mapper
以键值对的方式读取
extends Mapper<LongWritable, Text, Text, IntWritable>
public class Test {
/** * static 必不可少 * LongWritable 数据集文件的行号,输入参数 * Text 数据集文件一行的内容,输入参数 * Text map输出的key类型,输出参数 * IntWritable map输出的value类型,输出参数 * */ public static class Mappers extends Mapper<LongWritable, Text, Text, IntWritable>{
/** * key 与 Mapper<LongWritable, Text, Text, IntWritable>中的第一个参数类型一致 * value 与 Mapper<LongWritable, Text, Text, IntWritable>中的第二个参数类型一致 * 如果数据集中有10行数据,该方法将被调用10次 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //读取文件一行的内容,将其转换为字符串,文件的编码一定要是utf-8。 String text = value.toString(); System.out.println("value="+text);
String[] fields = text.split(","); //分隔成需要的字段
//write方法中的第一参数与Mapper<LongWritable, Text, Text, IntWritable>中的第三个参数类型一致 //write方法中的第二参数与Mapper<LongWritable, Text, Text, IntWritable>中的第四个参数类型一致 //将 key/vlaue 对 写入map的输出文件中, ,输出文件名为part-r-00000 context.write(new Text(fields[7].trim()), new IntWritable(1)); } }Reducer
/** * static 必不可少 * Text map输出文件中的key类型,输入参数 * IntWritable map输出文件中的value类型,输入参数 * Text reduce输出的key类型,输出参数 * IntWritable reduce输出的value类型,输出参数 * 该方法只被调用一次 */ public static class Reducers extends Reducer<Text, IntWritable, Text, IntWritable>{
/** * values 存放的是key对应的所有value的列表,来自于map的输出 */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for(IntWritable p : values){ count ++; } //将 key/vlaue 对 写入到输出文件,输出文件名为part-r-00000 context.write(key, new IntWritable(count)); } }Job实现
在Hadoop 2中,MapReduce是一种分布式处理框架,用于处理大规模数据集的计算任务。一个MapReduce作业由多个Map阶段和一个Reduce阶段组成,它们可以在集群中并行执行。
org.apache.hadoop.mapreduce.Job类是Hadoop中表示一个MapReduce作业的主要类。以下是关于Job类的一些重要方法和概念:
- 创建Job对象:使用
Job.getInstance()方法创建一个Job对象,并指定所在的集群和配置。 - 设置输入和输出路径:使用
Job.setInputFormatClass()方法指定输入文件的格式以及用FileInputFormat设置输入路径,使用Job.setOutputFormatClass()方法指定输出文件的格式以及用FileOutputFormat设置输出路径。 - 设置Mapper和Reducer类:使用
Job.setMapperClass()和Job.setReducerClass()方法设置自定义的Mapper和Reducer类。 - 设置Mapper和Reducer的输出键值对类型:使用
Job.setMapOutputKeyClass()和Job.setMapOutputValueClass()方法设置Mapper的输出键值对类型,使用Job.setOutputKeyClass()和Job.setOutputValueClass()方法设置Reducer的输出键值对类型。 - 设置要使用的资源文件和库文件:使用
Job.addFileToClassPath()方法添加要使用的资源文件、Job.addArchiveToClassPath()方法添加要使用的压缩库文件。 - 提交作业并等待完成:使用
Job.waitForCompletion()方法提交作业,并等待作业完成。
在 Hadoop 中,job.setInputFormatClass() 用于指定输入数据的格式。参数常见如下:
TextInputFormat:将输入文件视为逐行文本文件。KeyValueInputFormat:将输入文件视为键值对(key-value)文件。SequenceFileInputFormat:将输入文件视为序列文件,其中包含键值对数据。CombineTextInputFormat:类似于TextInputFormat,但在处理大型文本文件时能够更好地利用 Hadoop 的InputSplit功能。NLineInputFormat:根据指定的行数将输入文件划分为InputSplit。CustomInputFormat:根据用户的需求自定义的输入格式。
这只是一些常见的输入格式类,实际上还可以根据需要自定义输入格式类来满足特定的需求。
package org.example;
import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.util.Tool;
public class WordCountJob extends Configured implements Tool { @Override public int run(String[] strings) throws Exception { Job job = Job.getInstance(super.getConf(), "WordCount_Job");
job.setInputFormatClass(TextInputFormat.class); TextInputFormat.addInputPath(job, new Path("hdfs:///WordCount.input"));
job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("hdfs:///WordCount_Output")); boolean success = job.waitForCompletion(true); return success ? 0 : 1; }}执行程序
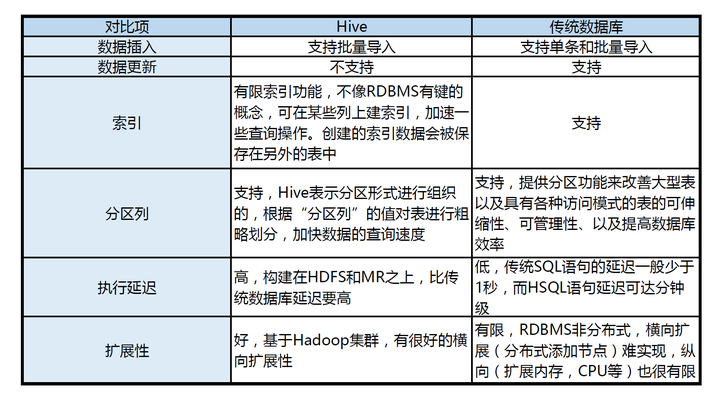
hadoop jar *****.jar your.package.name.YourMainClasHive操作
Hive数据仓库
数据仓库主要面对OLAP(联机分析处理),侧重决策分析。
Hive是依赖于Hadoop存在的,其次因为MapReduce语法较复杂,Hive可以将较简单的SQL语句转化成MapReduce进行计算!!!
[ ]
]
Mahout提供一些可扩展的机器学习领域的经典算法实现,用于创建商务智能(BI)应用程序
Beeline
Hive客户端工具后续将使用Beeline 替代HiveCLI ,并且后续版本也会废弃掉HiveCLI 客户端工具,Beeline是 Hive 0.11版本引入的新命令行客户端工具,它是基于SQLLine CLI的JDBC客户
数据初始化
schematool -initSchema -dbType mysql启动
两者,要么挂screen,要么挂hiveserver2
hive --service metastorehive --service hiveserver2Hive获取Mysql元数据的两种方式: ①Hive直连MySQL获取元数据 启动方式:只需直接启动Hive客户端,即可连接 ②Hive先连接Metastore服务,再通过 Metastore服务连接MySQL获取元数据
hive比较特殊,它既是自己的客户端,又是服务端。Hive充当客户端(是HDFS的客户端也是Metastore的客户端,也是Hive的客户端)又充当服务端(因为有Metastore服务和Hiveserver2服务配置) 因为在实际生产环境下,可能有多台Hive客户端(比如有:103、104、105三台机器),MySQL的 IP地址对外不暴露,只暴露给其中一台(假如暴露给103这台机器),那么其他客户端怎么连接呢?那么就需要在暴露的那台机器上启动Metastore服务,其他Hive客户端连接这个Metastore服务,进而达到连接Mysql获取元数据的目的。
hive是hadoop的客户端,同时hive本身也有客户端,Hiveserver2的beeline连接方式实际是Hive与Hive之间的服务端与客户端通过JDBC连接的方式
hiveserver2
HiveServer 是 Hive 的一个组件,它是 Hive 提供给外部客户端连接和交互的接口。HiveServer 允许用户通过各种编程语言(如 Java、Python、PHP 等)或工具(如 JDBC、ODBC 驱动)连接到 Hive,并执行 Hive 查询、操作数据等操作。
HiveServer 提供了两种不同的实现方式:
-
HiveServer1:HiveServer1 是旧版本的 HiveServer,它使用 Thrift 作为通信协议。HiveServer1 支持 Hive CLI 和其他的 Thrift 客户端连接,但不支持 JDBC 和 ODBC 连接。
-
HiveServer2:HiveServer2 是新版本的 HiveServer,它使用了更高级的 Thrift 通信协议,并提供了更多的功能和可扩展性。HiveServer2 支持 JDBC 和 ODBC 连接,可以通过各种编程语言和工具连接到 Hive 进行查询和操作。
使用 HiveServer,你可以将 Hive 集成到你的应用程序中,通过编程方式连接到 Hive 并执行 Hive 查询。这样,你可以使用 Hive 的强大的数据处理能力和 SQL 查询语言来处理大规模数据集。
在配置和使用 HiveServer 时,你需要指定 HiveServer 的监听地址、端口号、认证方式等配置,并确保 HiveServer 进程正在运行。一旦 HiveServer 运行起来,你就可以通过指定的连接方式和参数来连接到 HiveServer,并执行查询和操作。
Metastore
Hive 的 Metastore(元数据存储)是 Hive 的一个重要组件,它负责管理和存储 Hive 的元数据信息。元数据是描述数据的数据,它包含了表、分区、列、数据类型、表结构、表之间的关系等信息。
Hive 的 Metastore 将元数据存储在持久化的存储介质中,通常是一个关系型数据库(如 MySQL、PostgreSQL 等)。Metastore 将 Hive 的元数据信息组织成一个层次结构,包含数据库(database)、表(table)、分区(partition)等对象。
Metastore 提供了一组 API 和命令,用于管理和操作 Hive 的元数据。它负责处理表的创建、修改、删除,以及对表的元数据进行查询、检索等操作。Metastore 还支持表的分区管理,可以将表分成多个分区,每个分区可以根据不同的条件进行划分和管理。
Metastore 的主要功能包括:
-
元数据存储:Metastore 将 Hive 的元数据信息存储在持久化的存储介质中,以便在需要时进行检索和查询。
-
元数据管理:Metastore 提供了 API 和命令,用于管理和操作 Hive 的元数据。它可以创建、修改、删除表,管理分区等操作。
-
元数据查询:Metastore 提供了查询接口,可以根据条件查询表的元数据信息,如表的结构、列的属性等。
-
分区管理:Metastore 支持表的分区管理,可以将表分成多个分区,每个分区可以根据不同的条件进行划分和管理。
通过 Metastore,Hive 可以方便地管理和操作元数据信息,使得用户可以使用类似于 SQL 的语法来查询和操作大规模数据集。同时,Metastore 的使用还提高了 Hive 查询的性能,因为 Hive 可以利用元数据信息来进行查询优化和执行计划的生成。
HiveQL
Hadoop Hive(简称Hive)是一个基于Hadoop的数据仓库工具,它提供了一个类似于SQL的查询语言(HiveQL),用于处理和分析大规模的结构化和半结构化数据。
Hive 是为了方便数据分析人员使用 SQL 类似的查询语言来处理大规模数据而设计的,它将 SQL 查询转换为 Hadoop MapReduce 任务来执行。因此,Hive 可以让非程序员也能够使用 SQL 类似的语法来查询和分析大规模数据,而无需编写复杂的 MapReduce 程序。
Hive 使用 HiveQL(Hive Query Language)作为查询语言,HiveQL 类似于 SQL,但在语法和功能上有一些差异。HiveQL 支持常见的 SQL 操作,如 SELECT、JOIN、GROUP BY、WHERE 等,同时还支持用户自定义函数(UDF)、分区表、存储格式等特性。
Hive 的底层数据存储在 Hadoop 分布式文件系统(HDFS)中,并通过 Hive 的元数据存储(Metastore)来管理和查询数据的元数据信息。Hive 将数据存储为表的形式,表可以分成多个分区,每个分区可以根据不同的条件进行划分和管理。
使用 Hive,你可以通过 HiveQL 查询和分析大规模数据,利用 Hadoop 的并行计算能力来加速数据处理。Hive 还提供了丰富的内置函数和扩展功能,使得数据分析更加灵活和高效。
需要注意的是,Hive 不适用于实时数据处理和低延迟查询,因为它是基于批处理的模型。如果需要实时数据处理,可以考虑使用类似于 Apache Spark 的流式处理框架。
Hive中的表不支持直接定义主键约束,因为Hive是一个基于Hadoop的数据仓库系统,它的主要目标是提供大规模数据存储和查询的功能,而不是提供完整的事务支持。
表创建测试
CREATE TABLE IF NOT EXISTS test_table ( id INT, name STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILE;default创建的表,会直接放在warehouse下边
在创建Hive表时,默认行分隔符”^A”,列分隔符”\n”,这两项也是可以设置的。在实际开发中,一般默认使用默认的分隔符,当然有些场景下也会自定义分隔符。
数据行可能是单个文件(甚至可以以文本形式打开)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'ROW FORMAT DELIMITED FIELDS TERMINATED BY ','查看表的数据属性
desc table_3创建新表
create table table_3 as select name from test_table删库
drop database db_1查看表
SELECT * from test_table limit 2DML处理
数据源导入
LOAD DATA LOCAL INPATH '/root/abcd.txt' into db.table_2将文件中的数据导入(Load)到 Hive 表中
直接insert
INSERT INTO test_table VALUES (1, 'John');连接JDBC
与springboot貌似有依赖冲突,可能还有hive-common
<dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>3.1.3</version> <exclusions> <exclusion> <groupId>*</groupId> <artifactId>*</artifactId> </exclusion> </exclusions> </dependency>select操作
select concat("abcd","efgh")select concat_ws(".","com","baidu","tieba")select substr("apple",-4)select split("golden states"," ")select CURRENT_DATE()select unix_timestamp()select unix_timestamp("2030-08-08 08:00:00")select from_unixtime()select rand()SELECT nv1(NULL, "abcd");NVL函数的功能是实现空值的转换,根据第一个表达式的值是否为空值来返回相应的列名或表达式,主要用于对数据列上的空值进行处理,语法格式如
Hive实现WordCount
在Hive中实现WordCount算法可以通过以下步骤:
- 创建一个包含文本数据的表:首先,使用Hive创建一个包含文本数据的表,其中每一行表示一个文本文件中的内容,每个单词用空格或其他分隔符分隔。你可以使用如下的Hive语句创建表:
CREATE TABLE text_data (line STRING);- 导入文本数据:使用Hive的
LOAD DATA命令将文本数据导入到上述的text_data表中。假设数据文件data.txt包含文本数据,可以使用如下命令导入数据:
LOAD DATA INPATH '/data.txt' INTO TABLE text_data;- 编写WordCount查询:使用Hive的查询语法编写WordCount查询。以下是一个示例查询,可以计算每个单词的出现次数:
SELECT word, COUNT(*) AS countFROM ( SELECT explode(split(line, ',')) AS word FROM text_data) tWHERE word != ''GROUP BY wordORDER BY count DESC;上述查询中,首先使用split函数将每一行的内容拆分成单词,并使用explode函数将拆分后的单词展开成多个行。然后,将结果进行分组、计数和排序,以得到每个单词的出现次数。
- 运行查询:在Hive中运行上述查询,并查看结果。你可以使用Hive的命令行界面或其他Hive客户端运行查询。
请注意,为了更准确地进行WordCount,你可能需要进行一些文本处理和清洗操作,如删除标点符号、转换为小写等。你可以根据具体需求进行适当的修改。
貌似Druid可以统一MySQL与Hive
Druid
本来准备计划试试,但自己SpringBoot学艺不精,再加上最后选用了Django,项目后期就没有在考虑了
druid-spring-boot-starter整合hive遇到的一个小坑
Sqoop
Sqoop 2021年停止维护
我看组员最后数据分析用了SPSSPRO
PyHive
pip install saslpip install thriftpip install thrift-saslpip install PyHive但Windows下安装报错
C:\Users\Administrator\AppData\Local\Temp\pip-install-7_4i0p52\sasl_bd6a6fbee8074cf6814556fa3e26c960\sasl\saslwrapper.h(22): fatal error C1083: 无法打开包括文件: “sasl/sasl.h”: No such file or directory最后证明PyHive依赖于Linux的组件,在Ubuntu上运行起来了
insert overwrite操作
select * from emp;insert overwrite table emp select * from emp where emp_name is not null;select * from dept;在Hive中,DELETE操作的替代方式是使用INSERT INTO语句将要保留的数据插入到新的表中,然后重命名新表覆盖原始表。这种方式被称为“Insert-Overwrite”。
insert overwrite table orderCentos踩坑
ssh登录过慢
1.su (以root用户登录)2.vim /etc/ssh/sshd_config (编辑配置文件)3.输入 /, 查找GSSAPIAuthentication 赋值为 no(默认为yes)4.输入 /, 查找UseDNS,赋值为 no(该项默认不启用的,要把前面的#删除掉)————————————————版权声明:本文为CSDN博主「skyxiaolv」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/lixialv/article/details/107670539Themlef
最后项目结束答辩的其中一个成果,是做页面进行数据展示。整个小组里只有我能完成前端与后端的工作,为了省时间就只能选前后端一体的方案。SpringBoot+Themlef是我当时比较中意的一个方案
需要starter-web
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId></dependency>Layui
如果前后端是一体的话推荐使用这个
启动配置
SpringBoot整合Thymeleaf快速入门(附详细教程)
准表达式语法
Thymeleaf 模板引擎支持多种表达式:
- 变量表达式:${…}
- 选择变量表达式:*{…}
- 链接表达式:@{…}
- 国际化表达式:#{…}
- 片段引用表达式:~{…}
① 获取对象的属性和方法
使用变量表达式可以获取对象的属性和方法,例如,获取 person 对象的 lastName 属性,表达式形式如下:
${person.lastName}② 使用内置的基本对象
使用变量表达式还可以使用内置基本对象,获取内置对象的属性,调用内置对象的方法。 Thymeleaf 中常用的内置基本对象如下:
- #ctx :上下文对象;
- #vars :上下文变量;
- #locale:上下文的语言环境;
- #request:HttpServletRequest 对象(仅在 Web 应用中可用);
- #response:HttpServletResponse 对象(仅在 Web 应用中可用);
- #session:HttpSession 对象(仅在 Web 应用中可用);
- #servletContext:ServletContext 对象(仅在 Web 应用中可用)。
例如,我们通过以下 2 种形式,都可以获取到 session 对象中的 map 属性:
${#session.getAttribute('map')}${session.map}③ 使用内置的工具对象
除了能使用内置的基本对象外,变量表达式还可以使用一些内置的工具对象。
- strings:字符串工具对象,常用方法有:equals、equalsIgnoreCase、length、trim、toUpperCase、toLowerCase、indexOf、substring、replace、startsWith、endsWith,contains 和 containsIgnoreCase 等;
- numbers:数字工具对象,常用的方法有:formatDecimal 等;
- bools:布尔工具对象,常用的方法有:isTrue 和 isFalse 等;
- arrays:数组工具对象,常用的方法有:toArray、length、isEmpty、contains 和 containsAll 等;
- lists/sets:List/Set 集合工具对象,常用的方法有:toList、size、isEmpty、contains、containsAll 和 sort 等;
- maps:Map 集合工具对象,常用的方法有:size、isEmpty、containsKey 和 containsValue 等;
- dates:日期工具对象,常用的方法有:format、year、month、hour 和 createNow 等。
例如,我们可以使用内置工具对象 strings 的 equals 方法,来判断字符串与对象的某个属性是否相等,代码如下。
纯文本复制${#strings.equals('编程帮',name)}与js结合
必须单独创建一个变量
<script th:inline="javascript"> var fs1 = [[${fs1}]]; console.log(fs1); var user = /*[[${user}]]*/ null; console.log(user)</script>或者用each
<tr th:each="book : ${books}"> <td th:text="${book.author}"></td> <td th:text="${book.title}"></td> <td th:text="${book.url}"></td> <script th:inline="javascript">//一定要加上这句
function localRefresh() { // 装载局部刷新返回的页面 $('#table_refresh2').load("/local/"+[[${book.ID}]]);//这里直接可以使用thymeleaf中的变量,通过内联样式 } </script></tr>th语法
| 属性 | 描述 | 示例 |
|---|---|---|
| th:id | 替换 HTML 的 id 属性 | <input id="html-id" th:id="thymeleaf-id" /> |
| th:text | 文本替换,转义特殊字符 | <h1 th:text="hello,bianchengbang" >hello</h1> |
| th:utext | 文本替换,不转义特殊字符 | <div th:utext="'<h1>欢迎来到编程帮!</h1>'" >欢迎你</div> |
| th:object | 在父标签选择对象,子标签使用 *{…} 选择表达式选取值。 没有选择对象,那子标签使用选择表达式和 ${…} 变量表达式是一样的效果。 同时即使选择了对象,子标签仍然可以使用变量表达式。 | <div th:object="${session.user}" > <p th:text="*{fisrtName}">firstname</p></div> |
| th:value | 替换 value 属性 | <input th:value = "${user.name}" /> |
| th:with | 局部变量赋值运算 | <div th:with="isEvens = ${prodStat.count}%2 == 0" th:text="${isEvens}"></div> |
| th:style | 设置样式 | <div th:style="'color:#F00; font-weight:bold'">编程帮 www.biancheng.net</div> |
| th:onclick | 点击事件 | <td th:onclick = "'getInfo()'"></td> |
| th:each | 遍历,支持 Iterable、Map、数组等。 | <table> <tr th:each="m:${session.map}"> <td th:text="${m.getKey()}"></td> <td th:text="${m.getValue()}"></td> </tr></table> |
| th:if | 根据条件判断是否需要展示此标签 | <a th:if ="${userId == collect.userId}"> |
| th:unless | 和 th:if 判断相反,满足条件时不显示 | <div th:unless="${m.getKey()=='name'}" ></div> |
| th:switch | 与 Java 的 switch case语句类似 通常与 th:case 配合使用,根据不同的条件展示不同的内容 | <div th:switch="${name}"> <span th:case="a">编程帮</span> <span th:case="b">www.biancheng.net</span></div> |
| th:fragment | 模板布局,类似 JSP 的 tag,用来定义一段被引用或包含的模板片段 | <footer th:fragment="footer">插入的内容</footer> |
| th:insert | 布局标签; 将使用 th:fragment 属性指定的模板片段(包含标签)插入到当前标签中。 | <div th:insert="commons/bar::footer"></div> |
| th:replace | 布局标签; 使用 th:fragment 属性指定的模板片段(包含标签)替换当前整个标签。 | <div th:replace="commons/bar::footer"></div> |
| th:selected | select 选择框选中 | <select> <option>---</option> <option th:selected="${name=='a'}"> 编程帮 </option> <option th:selected="${name=='b'}"> www.biancheng.net </option></select> |
| th:src | 替换 HTML 中的 src 属性 | <img th:src="@{/asserts/img/bootstrap-solid.svg}" src="asserts/img/bootstrap-solid.svg" /> |
| th:inline | 内联属性; 该属性有 text、none、javascript 三种取值, 在 | <script type="text/javascript" th:inline="javascript"> var name = /*[[${name}]]*/ 'bianchengbang'; alert(name)</script> |
| th:action | 替换表单提交地址 | <form th:action="@{/user/login}" th:method="post"></form> |
Example
index.html
<!DOCTYPE html><html xmlns:th="http://www.thymeleaf.org"><head> <title>Thymeleaf的入门</title> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/></head><body> <p th:text="${hello}"></p></body></html>index.java
import org.springframework.stereotype.Controller;import org.springframework.ui.Model;import org.springframework.web.bind.annotation.RequestMapping;
/** * @author MocusEZ * @date 2023/6/23 14:42 */@Controller@RequestMapping("/test")public class TestController {
/*** * 访问/test/hello 跳转到templates_1页面 * @param model * @return */ @RequestMapping("/hello") public String hello(Model model){ model.addAttribute("hello","What a wonderful world!"); return "index"; }}ECharts测试
数据展示选用了ECharts组件,效果看起来不错。
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title>ECharts</title> <!-- 引入刚刚下载的 ECharts 文件 --> <script src="echarts.min.js"></script> </head> <body> <!-- 为 ECharts 准备一个定义了宽高的 DOM --> <div id="main" style="width: 600px;height:400px;"></div> <script type="text/javascript"> // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据 var option = { title: { text: 'Hello Wolrd' }, tooltip: {}, legend: { data: ['销量'] }, xAxis: { data: ['衬衫', '羊毛衫', '雪纺衫', '裤子', '高跟鞋', '袜子'] }, yAxis: {}, series: [ { name: '销量', type: 'bar', data: [5, 20, 36, 10, 10, 20] } ] };
// 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); </script> </body></html>图表容器及其大小
初始化
在 HTML 中定义有宽度和高度的父容器(推荐)
通常来说,需要在 HTML 中先定义一个 <div> 节点,并且通过 CSS 使得该节点具有宽度和高度。初始化的时候,传入该节点,图表的大小默认即为该节点的大小,除非声明了 opts.width 或 opts.height 将其覆盖。
<div id="main" style="width: 600px;height:400px;"></div><script type="text/javascript"> var myChart = echarts.init(document.getElementById('main'));</script>需要注意的是,使用这种方法在调用 echarts.init 时需保证容器已经有宽度和高度了。
指定图表的大小
如果图表容器不存在宽度和高度,或者,你希望图表宽度和高度不等于容器大小,也可以在初始化的时候指定大小。
<div id="main"></div><script type="text/javascript"> var myChart = echarts.init(document.getElementById('main'), null, { width: 600, height: 400 });</script>响应容器大小的变化
https://echarts.apache.org/handbook/zh/concepts/chart-size
样式
ECharts5 除了一贯的默认主题外,还内置了'dark'主题。可以像这样切换成深色模式:
var chart = echarts.init(dom, 'dark');数据集
数据集(dataset)是专门用来管理数据的组件。虽然每个系列都可以在 series.data 中设置数据,但是从 ECharts4 支持数据集开始,更推荐使用数据集来管理数据。因为这样,数据可以被多个组件复用,也方便进行 “数据和其他配置” 分离的配置风格。毕竟,在运行时,数据是最常改变的,而其他配置大多并不会改变。
在系列中设置数据
option = { xAxis: { type: 'category', data: ['Matcha Latte', 'Milk Tea', 'Cheese Cocoa', 'Walnut Brownie'] }, yAxis: {}, series: [ { type: 'bar', name: '2015', data: [89.3, 92.1, 94.4, 85.4] }, { type: 'bar', name: '2016', data: [95.8, 89.4, 91.2, 76.9] }, { type: 'bar', name: '2017', data: [97.7, 83.1, 92.5, 78.1] } ]};这种方式的优点是,适于对一些特殊的数据结构(如“树”、“图”、超大数据)进行一定的数据类型定制。 但是缺点是,常需要用户先处理数据,把数据分割设置到各个系列(和类目轴)中。此外,不利于多个系列共享一份数据,也不利于基于原始数据进行图表类型、系列的映射安排。
在数据集中设置数据
而数据设置在 数据集(dataset) 中,会有这些好处:
- 能够贴近数据可视化常见思维方式:(I)提供数据,(II)指定数据到视觉的映射,从而形成图表。
- 数据和其他配置可以被分离开来。数据常变,其他配置常不变。分开易于分别管理。
- 数据可以被多个系列或者组件复用,对于大数据量的场景,不必为每个系列创建一份数据。
- 支持更多的数据的常用格式,例如二维数组、对象数组等,一定程度上避免使用者为了数据格式而进行转换。
下面是一个最简单的 dataset 的例子:
option = { legend: {}, tooltip: {}, dataset: { // 提供一份数据。 source: [ ['product', '2015', '2016', '2017'], ['Matcha Latte', 43.3, 85.8, 93.7], ['Milk Tea', 83.1, 73.4, 55.1], ['Cheese Cocoa', 86.4, 65.2, 82.5], ['Walnut Brownie', 72.4, 53.9, 39.1] ] }, // 声明一个 X 轴,类目轴(category)。默认情况下,类目轴对应到 dataset 第一列。 xAxis: { type: 'category' }, // 声明一个 Y 轴,数值轴。 yAxis: {}, // 声明多个 bar 系列,默认情况下,每个系列会自动对应到 dataset 的每一列。 series: [{ type: 'bar' }, { type: 'bar' }, { type: 'bar' }]};数据到图形的映射
如上所述,数据可视化的一个常见思路是:(I)提供数据,(II)指定数据到视觉的映射。
简而言之,可以进行这些映射的设定:
- 指定
数据集的列(column)还是行(row)映射为系列(series)。这件事可以使用 series.seriesLayoutBy 属性来配置。默认是按照列(column)来映射。 - 指定维度映射的规则:如何从 dataset 的维度(一个“维度”的意思是一行/列)映射到坐标轴(如 X、Y 轴)、提示框(tooltip)、标签(label)、图形元素大小颜色等(visualMap)。这件事可以使用 series.encode 属性,以及 visualMap 组件来配置(如果有需要映射颜色大小等视觉维度的话)。上面的例子中,没有给出这种映射配置,那么 ECharts 就按最常见的理解进行默认映射:X 坐标轴声明为类目轴,默认情况下会自动对应到
dataset.source中的第一列;三个柱图系列,一一对应到dataset.source中后面每一列。
下面详细解释这些映射的设定。
把数据集(dataset)的行或列映射为系列(series)
有了数据表之后,使用者可以灵活地配置:数据如何对应到轴和图形系列。
用户可以使用 seriesLayoutBy 配置项,改变图表对于行列的理解。seriesLayoutBy 可取值:
'column': 默认值。系列被安放到dataset的列上面。'row': 系列被安放到dataset的行上面。
看这个例子:
option = { legend: {}, tooltip: {}, dataset: { source: [ ['product', '2012', '2013', '2014', '2015'], ['Matcha Latte', 41.1, 30.4, 65.1, 53.3], ['Milk Tea', 86.5, 92.1, 85.7, 83.1], ['Cheese Cocoa', 24.1, 67.2, 79.5, 86.4] ] }, xAxis: [ { type: 'category', gridIndex: 0 }, { type: 'category', gridIndex: 1 } ], yAxis: [{ gridIndex: 0 }, { gridIndex: 1 }], grid: [{ bottom: '55%' }, { top: '55%' }], series: [ // 这几个系列会出现在第一个直角坐标系中,每个系列对应到 dataset 的每一行。 { type: 'bar', seriesLayoutBy: 'row' }, { type: 'bar', seriesLayoutBy: 'row' }, { type: 'bar', seriesLayoutBy: 'row' }, // 这几个系列会出现在第二个直角坐标系中,每个系列对应到 dataset 的每一列。 { type: 'bar', xAxisIndex: 1, yAxisIndex: 1 }, { type: 'bar', xAxisIndex: 1, yAxisIndex: 1 }, { type: 'bar', xAxisIndex: 1, yAxisIndex: 1 }, { type: 'bar', xAxisIndex: 1, yAxisIndex: 1 } ]};坐标轴
x 轴、y 轴
x 轴和 y 轴都由轴线、刻度、刻度标签、轴标题四个部分组成。部分图表中还会有网格线来帮助查看和计算数据
option = { xAxis: { type: 'time', name: '销售时间' // ... }, yAxis: { type: 'value', name: '销售数量' // ... } // ...};Example
图左侧的 y 轴代表东京月平均气温,右侧的 y 轴表示东京降水量,x 轴表示时间。两组 y 轴在一起,反映了平均气温和降水量间的趋势关系。
option = { tooltip: { trigger: 'axis', axisPointer: { type: 'cross' } }, legend: {}, xAxis: [ { type: 'category', axisTick: { alignWithLabel: true }, data: [ '1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月' ] } ], yAxis: [ { type: 'value', name: '降水量', min: 0, max: 250, position: 'right', axisLabel: { formatter: '{value} ml' } }, { type: 'value', name: '温度', min: 0, max: 25, position: 'left', axisLabel: { formatter: '{value} °C' } } ], series: [ { name: '降水量', type: 'bar', yAxisIndex: 0, data: [6, 32, 70, 86, 68.7, 100.7, 125.6, 112.2, 78.7, 48.8, 36.0, 19.3] }, { name: '温度', type: 'line', smooth: true, yAxisIndex: 1, data: [ 6.0, 10.2, 10.3, 11.5, 10.3, 13.2, 14.3, 16.4, 18.0, 16.5, 12.0, 5.2 ] } ]};图例
option = { legend: { // Try 'horizontal' orient: 'vertical', right: 10, top: 'center' }, dataset: { source: [ ['product', '2015', '2016', '2017'], ['Matcha Latte', 43.3, 85.8, 93.7], ['Milk Tea', 83.1, 73.4, 55.1], ['Cheese Cocoa', 86.4, 65.2, 82.5], ['Walnut Brownie', 72.4, 53.9, 39.1] ] }, xAxis: { type: 'category' }, yAxis: {}, series: [{ type: 'bar' }, { type: 'bar' }, { type: 'bar' }]};事件与行为
在 Apache ECharts 的图表中用户的操作将会触发相应的事件。开发者可以监听这些事件,然后通过回调函数做相应的处理,比如跳转到一个地址,或者弹出对话框,或者做数据下钻等等。
ECharts 中的事件名称对应 DOM 事件名称,均为小写的字符串,如下是一个绑定点击操作的示例。
myChart.on('click', function(params) { // 控制台打印数据的名称 console.log(params.name);});鼠标事件处理
ECharts 支持常规的鼠标事件类型,包括 'click'、 'dblclick'、 'mousedown'、 'mousemove'、 'mouseup'、 'mouseover'、 'mouseout'、 'globalout'、 'contextmenu' 事件。下面先来看一个简单的点击柱状图后打开相应的百度搜索页面的示例。
// 基于准备好的dom,初始化ECharts实例// var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据var option = { xAxis: { data: ['衬衫', '羊毛衫', '雪纺衫', '裤子', '高跟鞋', '袜子'] }, yAxis: {}, series: [ { name: '销量', type: 'bar', data: [5, 20, 36, 10, 10, 20] } ]};// 使用刚指定的配置项和数据显示图表。myChart.setOption(option);// 处理点击事件并且跳转到相应的百度搜索页面myChart.on('click', function(params) { window.open('https://www.baidu.com/s?wd=' + encodeURIComponent(params.name));});常用图标
柱状图
简单柱状图
option = { xAxis: { data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'] }, yAxis: {}, series: [ { type: 'bar', data: [23, 24, 18, 25, 27, 28, 25] } ]};多系列柱状图
option = { xAxis: { data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'] }, yAxis: {}, series: [ { type: 'bar', data: [23, 24, 18, 25, 27, 28, 25] }, { type: 'bar', data: [26, 24, 18, 22, 23, 20, 27] } ]};堆叠柱状图
option = { xAxis: { data: ['A', 'B', 'C', 'D', 'E'] }, yAxis: {}, series: [ { data: [10, 22, 28, 43, 49], type: 'bar', stack: 'x' }, { data: [5, 4, 3, 5, 10], type: 'bar', stack: 'x' } ]};动态排序柱状图
- 柱状图系列的
realtimeSort设为true,表示开启该系列的动态排序效果 yAxis.inverse设为true,表示 Y 轴从下往上是从小到大的排列yAxis.animationDuration建议设为300,表示第一次柱条排序动画的时长yAxis.animationDurationUpdate建议设为300,表示第一次后柱条排序动画的时长- 如果想只显示前 n 名,将
yAxis.max设为 n - 1,否则显示所有柱条 xAxis.max建议设为'dataMax'表示用数据的最大值作为 X 轴最大值,视觉效果更好- 如果想要实时改变标签,需要将
series.label.valueAnimation设为true animationDuration设为0,表示第一份数据不需要从0开始动画(如果希望从0开始则设为和animationDurationUpdate相同的值)animationDurationUpdate建议设为3000表示每次更新动画时长,这一数值应与调用setOption改变数据的频率相同- 以
animationDurationUpdate的频率调用setInterval,更新数据值,显示下一个时间点对应的柱条排序
var data = [];for (let i = 0; i < 5; ++i) { data.push(Math.round(Math.random() * 200));}
option = { xAxis: { max: 'dataMax' }, yAxis: { type: 'category', data: ['A', 'B', 'C', 'D', 'E'], inverse: true, animationDuration: 300, animationDurationUpdate: 300, max: 2 // only the largest 3 bars will be displayed }, series: [ { realtimeSort: true, name: 'X', type: 'bar', data: data, label: { show: true, position: 'right', valueAnimation: true } } ], legend: { show: true }, animationDuration: 3000, animationDurationUpdate: 3000, animationEasing: 'linear', animationEasingUpdate: 'linear'};
function update() { var data = option.series[0].data; for (var i = 0; i < data.length; ++i) { if (Math.random() > 0.9) { data[i] += Math.round(Math.random() * 2000); } else { data[i] += Math.round(Math.random() * 200); } } myChart.setOption(option);}
setInterval(function() { update();}, 3000);阶梯瀑布图
Apache ECharts 中并没有单独的瀑布图类型,但是我们可以使用堆叠的柱状图模拟该效果。
假设数据数组中的值是表示对前一个值的增减:
var data = [900, 345, 393, -108, -154, 135, 178, 286, -119, -361, -203];也就是第一个数据是 900,第二个数据 345 表示的是在 900 的基础上增加了 345……将这个数据展示为阶梯瀑布图时,我们可以使用三个系列:第一个是不可交互的透明系列,用来实现“悬空”的柱状图效果;第二个系列用来表示正数;第三个系列用来表示负数。
var data = [900, 345, 393, -108, -154, 135, 178, 286, -119, -361, -203];var help = [];var positive = [];var negative = [];for (var i = 0, sum = 0; i < data.length; ++i) { if (data[i] >= 0) { positive.push(data[i]); negative.push('-'); } else { positive.push('-'); negative.push(-data[i]); }
if (i === 0) { help.push(0); } else { sum += data[i - 1]; if (data[i] < 0) { help.push(sum + data[i]); } else { help.push(sum); } }}
option = { title: { text: 'Waterfall' }, grid: { left: '3%', right: '4%', bottom: '3%', containLabel: true }, xAxis: { type: 'category', splitLine: { show: false }, data: (function() { var list = []; for (var i = 1; i <= 11; i++) { list.push('Oct/' + i); } return list; })() }, yAxis: { type: 'value' }, series: [ { type: 'bar', stack: 'all', itemStyle: { normal: { barBorderColor: 'rgba(0,0,0,0)', color: 'rgba(0,0,0,0)' }, emphasis: { barBorderColor: 'rgba(0,0,0,0)', color: 'rgba(0,0,0,0)' } }, data: help }, { name: 'positive', type: 'bar', stack: 'all', data: positive }, { name: 'negative', type: 'bar', stack: 'all', data: negative, itemStyle: { color: '#f33' } } ]};折线图
摆上去不太好看,最后试了一下就没再去管了
Linux基本指令
mkdir -p a/b/cJava基础Note
Java中的Map是一种对键值对进行存储的数据结构。它提供了一种通过键快速查找和访问对应的值的方式,类似于字典或哈希表。
https://mvnrepository.com/artifact/com.mysql/mysql-connector-j
Mysql 8.0处理
mysql8.0 报错Public Key Retrieval is not allowed
补充资料
如何用形象的比喻描述大数据的技术生态?Hadoop、Hive、Spark 之间是什么关系?
有了MapReduce,Tez和Spark之后,程序员发现,MapReduce的程序写起来真麻烦。他们希望简化这个过程。这就好比你有了汇编语言,虽然你几乎什么都能干了,但是你还是觉得繁琐。你希望有个更高层更抽象的语言层来描述算法和数据处理流程。于是就有了Pig和Hive。Pig是接近脚本方式去描述MapReduce,Hive则用的是SQL。它们把脚本和SQL语言翻译成MapReduce程序,丢给计算引擎去计算,而你就从繁琐的MapReduce程序中解脱出来,用更简单更直观的语言去写程序了。
除此之外,还有一些更特制的系统/组件,比如Mahout是分布式机器学习库,Protobuf是数据交换的编码和库,ZooKeeper是高一致性的分布存取协同系统,等等。
作者:Xiaoyu Ma 链接:https://www.zhihu.com/question/27974418/answer/38965760 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
HDFS 被对象存储所取代,由 AWS S3 主导。MapReduce 已经被 Spark 所取代,Spark 也逐渐减少了对 Hadoop 的依赖性。Yarn 正在被像 Kubernetes 这样的技术取代。此外,Hive 的查询引擎组件在性能和采用方面已经被 Presto/Trino 超越。
Hive可以认为是MapReduce的一个包装,把好写的HQL转换为的MapReduce程序,本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表是纯逻辑表。hive需要用到hdfs存储文件,需要用到MapReduce计算框架
HBase:是一个Hadoop的数据库,一个分布式、可扩展、大数据的存储。hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。!!!
最开始是hadoop ,yarn+hdfs+mr全套的大数据处理系统,后来mr写起来太费事了,能不能简单点完成数据分析工作,就有了hive, sql化方式完成数据处理过程。再后来觉得觉得需要一个低延时查询东西,就有了hbase.
HDFS的具备存算一体的特性
但对象存储让存储与运算解耦
数据大屏方案
MySQL拯救记录
帮别人配置环境时他们自己忘记初始密码了,去CSDN上找方案找解决方案
Nohup使用
nohup 是 Linux 中的一个命令,用于在后台运行命令,并且忽略所有的挂起信号(SIGHUP)。该命令通常用于在登录会话结束时仍然继续运行进程。
nohup 命令的使用方式如下:
nohup command [options] [arguments] &其中,command 是要在后台运行的命令,options 是命令的选项,arguments 是命令的参数。& 符号用于将命令放到后台执行。
使用nohup命令后,命令的输出会被重定向到一个名为 nohup.out 的文件中。如果当前目录下已经存在 nohup.out 文件,则输出会追加到该文件中。如果不想产生 nohup.out 文件,可以将输出重定向到其他文件。
以下是一个使用 nohup 命令的示例:
nohup ./myprogram -a -b > output.log &上述命令会在后台运行 myprogram 程序,并将程序的输出重定向到 output.log 文件中。同时,通过 & 符号将命令放到后台执行。
使用 nohup 命令可以让命令在后台长时间运行,即使关闭终端或断开登录会话,进程也会继续执行。同时,输出文件 nohup.out 可以作为查看命令的输出和日志的便捷方式。
nohup的程序只能ps杀掉
ps aux | grep <程序名称>kill <PID>Fedora-CoreOS
详细经历可以看这里:
Butane
Butane (formerly the Fedora CoreOS Config Transpiler, FCCT) translates human readable Butane Configs into machine readable Ignition Configs. See the getting started guide for how to use Butane and the configuration specifications for everything Butane configs support.
https://github.com/coreos/butane
https://coreos.github.io/butane/specs/
使用Docker启动Hive
3.1.3的官方镜像用不了,用的是4.0的alpha2
里面是derby数据库,且没有使用HDFS
docker run -d -p 10000:10000 -p 10002:10002 -p 50070:50070 --env SERVICE_NAME=hiveserver2 --name hive4 apache/hive:4.0.0-alpha-2docker exec -it hive4 beeline -u 'jdbc:hive2://localhost:10000/'RPM基本指令
安装
rpm -i package_name.rpm卸载
要在CentOS中卸载软件包,可以按照以下步骤进行操作:
-
使用以下命令来列出已安装的软件包:
rpm -qa | grep package_name将
package_name替换为要卸载的软件包的名称。或者,如果您知道软件包的详细名称,也可以使用以下命令:
rpm -qa | grep -i "detailed_package_name"将
detailed_package_name替换为要卸载的软件包的详细名称。 -
找到要卸载的软件包后,使用以下命令进行卸载:
sudo rpm -e package_name或者,如果您知道软件包的详细名称,可以使用以下命令:
sudo rpm -e detailed_package_name上述命令将卸载指定的软件包。
注意:使用
rpm -e命令卸载软件包时要非常小心,确保您选择正确的软件包。卸载软件包可能会导致其他软件包不可用或系统功能受损。 -
执行卸载命令后,系统可能会提示您输入
sudo密码。输入密码后,按下Enter键继续卸载。 -
卸载完成后,系统将不再显示软件包的相关信息。
请注意,有些软件包可能有其他的卸载方法,如使用yum命令。可以查阅软件包的官方文档或开发人员的指南,以获取更详细的卸载说明。
更新
升级
yum update升级整个CentOS系统:
yum upgrade删除软件包:
yum remove package_name设置新的主机名
hostnamectl set-hostname new_hostnamehosts文件
Linux系统下修改/etc/hosts文件
BI工具
不少商业公司使用Business intelligence这样的系统做数据报表,其他不编程的小组就是采用这样的方案
Superset
DataEase
tablue
LastDay
我们小组选的是做西安高校的录取情况,下面记录的是SQL语句的调试情况(很多都是靠ChatGPT生成的doge)
SELECT admission_year,category,college_name,enrolled_numberFROM shannxi_college_admission where category="理工" and college_name="西安理工大学";SELECT sum(enrolled_number)FROM shannxi_college_admission where category="理工" and college_name="西安理工大学";SELECT admission_year, college_name, sum(enrolled_number) as enrolled_numberFROM shannxi_college_admissionWHERE category="理工"AND admission_year BETWEEN 2015 and 2022AND college_name IN ("西北农林科技大学", "西北大学", "西北工业大学", "西北政法大学", "西安交通大学", "西安交通大学(医学部)", "西安外国语大学", "西安工业大学", "西安工程大学", "西安建筑科技大学", "西安理工大学", "西安电子科技大学", "西安科技大学", "西安邮电大学","陕西师范大学","陕西科技大学")GROUP BY admission_year, college_name;结语
本轮生产实习为期10天,西安软件新城的伙食还不错。就是中午不睡觉有点顶不住,早上得在西安二环路上堵一个小时才能到实习地点,下午5点钟回学校只要30分钟。
最大的收获就是知道了什么是Hadoop,并且熟悉了Hive用法。感觉这种东西除非工作,平时是用不上这种东西的