
VLDB23论文阅读:Analyzing the Impact of Cardinality Estimation on Execution Plans in Microsoft SQL Server
这篇文章在CMU-15799的Lecture #14被提及,Andy提到微软的SQL Server拥有目前数据库中最好的Query Optimizer。而这篇来自微软研究人员的文章会介绍Query Optimize中最关键的一环:Cardinality Estimation
CMU提供的论文下载地址:https://15799.courses.cs.cmu.edu/spring2025/papers/14-cardinalities2/lee-vldb2023.pdf
INTRODUCTION
Cardinality estimation, the task of estimating the number of output rows for a SQL expression, is one of the challenging problems in query optimization
这里需要给不太了解Query Optimizer的人介绍下:数据库中的 Cardinality Estimation(基数估计) 是查询优化器的核心组成部分,它用于估计查询中各个中间结果(如某一列、某个连接条件、某个过滤条件等)返回的行数或值的数量,会直接影响到生成物理计划的质量
下面内容当中,会把Cardinality Estimaition简化为CE这个缩写
query optimizers on modern execution engines have the ability to use query execution techniques at runtime that can potentially mask (i.e., mitigate) the adverse impact of CE errors by reducing the latency of the plan obtained using estimated cardinalities.
“降低CE获得的计划的延迟来掩盖CE错误的不利影响” 即不应该过度追求生成计划的完美,而应该在生成计划的延迟与执行速度上达成平衡
To conduct our evaluation on the Microsoft SQL Server query optimizer, we needed to develop a new cardinality injection API, such that when the query optimizer requests the cardinality of a logical sub-expression of the query, we are able to inject a value that overrides the cardinality estimated by the optimizer’s built-in cardinality estimation model.
“cardinality injection API” 有意思,头一回听说这东西
1.1 Key Findings
这一块内容是将如何CE的优化是如何快的,相比一定是有提升的

We find that bitmap filtering is more frequently used in columnstores than rowstores because they require Index Scan and Hash Join operators, which are more predominant in columnstores.
详见6.1
1.2 Open Questions
The choice of appropriate physical operators for aggregation and join is an important area where existing runtime execution techniques are unable to mask the impact of inaccurate CE.
没太明白,想说的是需要新的Physical Operator能面对CE错误更加有弹性?(那会是什么东西?)
MICROSOFT SQL SERVER QUERY OPTIMIZER
2.1 Overview
Microsoft SQL Server’s query optimizer uses the Cascades framework’s [27] extensible optimizer architecture.
Cascades也是今年CMU-15799讲的重点内容
The optimizer uses two kinds of rules: transformation rules that map one algebraic expression into another (i.e., logical expression → logical expression) and implementation rules that map an algebraic expression into an operator tree (i.e., logical expression → physical operator tree)
简要的阐述了下Cascades
Bitmap filtering: Microsoft SQL Server uses bitmaps to perform a semi-join reduction for plans containing Hash Join operators. This technique performs early filtering of rows that will not qualify a join …… Bitmap pushdown in Microsoft SQL Server are performed on operators in the final plan chosen by the optimizer.
哦?那听起来不错👍
Adaptive join: The Microsoft SQL Server optimizer can use the adaptive join operator [6], which enables the choice of Hash Join or Nested Loops join method to be deferred to runtime until after the first join input has been scanned
Adaptive join? Mark下,最近准备在做了
2.2 Physical design
In Microsoft SQL Server, indexes fall into one of two categories: rowstore and columnstore
Microsoft SQL Server既有列存,也有行存(但却不属于HTAP的范畴?应该是分开的两类)
RowStore使用B+树,ColumnStore则具备要压缩率
2.3 API for exact cardinality injection
We extend the Microsoft SQL Server query optimizer with two APIs (see Figure 2):
(1) cardinality injection, which allows a client to inject a cardinality value for a specific memogroup during optimization, thereby overriding the optimizer estimated cardinality, and
(2) SQL decoding, which enables a client to obtain a valid and logically equivalent SQL statement corresponding to a memogroup.

Limitations of cardinality injection: There are some cardinalities used by the optimizer for which we are unable to inject cardinalities, and therefore the optimizer falls back to its default cardinality estimation logic in these cases.
并非所有都能Inject Cardinality,有些关于MemoGroup的操作就不行
EVALUATION SETUP AND METHODOLOGY
3.1 Workloads
(1) CE benchmarks: JOB [33], CEB [38], STATS [28]
(2) Industry benchmarks: TPC-DS, modified industry benchmarks DSB, TPC-H
- Real workloads: a suite of real queries over 6 different real databases. Both databases and queries were collected from customers of Microsoft SQL Server
• REAL1: Analyzes sales and inventory data for a US bookstore chain using dimensions of time, item, store, merchant etc.
• REAL2: Analyzes products and orders for an international cosmetic retailer.
• REAL3: Internal application that stores and queries the catalog of a source control system.
• REAL4: ERP application that analyzes retail invoices and sales by time, customer, point of sale etc.
• REAL5 and REAL6: Internal applications tracking agreements, customers and sales of products/services.
Andy好像在课上说过这些案例来源于微软的用户

3.2 Methodology
Our evaluation varies the following dimensions:
(1) Cardinality: {Optimizer-Est, Exact}
(2) Physical Design: {Rowstore, Columnstore}. For rowstore, for real workloads, we retain the original physical design present in the database. For all other workloads, we create indexes recommended by Microsoft SQL Server Database Engine Tuning Advisor (DTA) tool. For columnstores, we create one clustered columnstore index on each table.
(3) For Parallelism, Bitmaps and Adaptive Join, we run with each feature turned On/Off. We run each query in isolation with a cold cache i.e., the buffer pool is reset prior to each execution using dbcc dropcleanbuffers
RESULTS: EXECUTION-TIME OPTIMIZATIONS TURNED OFF
In particular, we use serial plans only (i.e., disable multicore parallelism), and turn off bitmap filtering and adaptive join techniques.
这一章占据了文章的很大篇幅,在我看来像一种消融实验,检查各个Optimization的实际作用
实验将Physical Operator分为4类
(1) Seek operators, i.e., operators that access base tables using random I/O
(2) Scan operators, i.e. , operators that access base tables using sequential I/O
(3) Non-leaf operators (e.g., physical join operators, sort, hash aggregate, …)
(4) A catch-all category where none of the conditions (1)-(3) apply and the elapsed time improvement is spread across multiple leaf and/or non-leaf operators.

但大多数是定量分析,反倒没什么值得说的😂想了解的可以看论文本体
Figure 3(a) shows for each workload the percentage of queries that improve (green bar) or regress (red bar) 2× or more when using exact cardinalities.
Figure 3(b) shows the improvement or regression in total elapsed time, i.e., sum of elapsed time over all queries in the workload. In 7 workloads we observe more than 40% improvement in total elapsed time,

这里可能会有人对文中的“absolute time regression”感到疑惑,实际上就是性能退化的意思
Example 4.1. An example query of first category, JOB Q17a, with its before and after plans are shown in Figure 4. The expensive Index Seek operators in Porig which contributes most to its elapsed time are shown in color. In Pexact the Index Nested Loops Join with table “name” is replaced with a Merge Join with an Index Scan of the “name” table, and the number of seeks for the table “cast_info” are significantly reduced due to join order change.

使用准确的CE后,原本和 name 表的 Index Nested Loop Join 被替换成了 Merge Join + Scan,从而提高了效率

对于TPC-H Q3,提供准确的CE后,可以不查找lineitem表
而在实际测试场景中,提供准确的CE后,Non-leaf operators (Sort and StreamAgg)使用了更小的数据

同理,提供准确CE后,Join Order也会调整为更为合理的顺序
The three major components of the query optimizer are cardinality estimation, cost model and search
啧,cardinality estimation, cost model and search,有意思
文中还提到了Cost Estimation对列存的影响
Figure 8(a) shows the percentage of queries for each workload with 2× or more improvement in elapsed time (green bar) and 2× or more regression in elapsed time (red bar).

SENSITIVITY TO CARDINALITY ERRORS
这个章节主要是关于两个问题:
(1) How few memogroups can we inject with exact CE and still get to the same plan as injecting all memogroups with exact CE?
- How large CE errors can be tolerated by the optimizer without significantly affecting plan quality?
5.1 Essential set of memogroups

对memogroup进行消融实验
The algorithm initializes the essential set to the set of all memogroups and then iteratively shrinks the set by attempting to remove a memogroup in each iteration.
这部分内容并没有明确答复,并不是所有 memogroup 都需要准确的基数估计,只有少量“关键 memogroups”真正决定了优化器是否能生成最优执行计划(Pexact)
5.2 Impact of varying CE error
The impact of varying q-error on plan quality is captured using box plots for each ε value in Figure 11. The outliers are shown as dots in the figure. The y-axis is the suboptimality ratio of the plan with respect to elapsed time of Pexact and x-axis is ε.
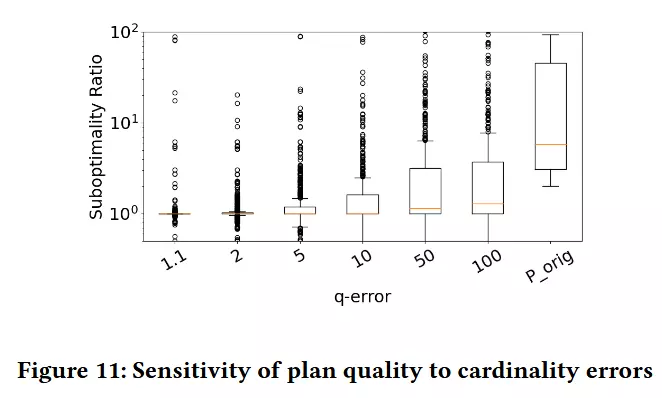
同样,这一部分内容的结论也比较模糊,CE Arrow的影响还和计划执行的事件有关——可以理解为执行时间越短,CE error的影响就越小
EFFECT OF RUNTIME TECHNIQUES: BITMAP FILTERING AND ADAPTIVE JOIN
这里Bitmap Filter和Adaptive Join是微软团队提供的优化
(i) {Opt-Est cardinalities, Techniqueoff}
(ii) {Exact cardinality, Technique-off}
(iii) {Opt-Est cardinalities,Technique-on}
(iv) {Exact cardinality, Technique-on}
6.1 Bitmap filtering
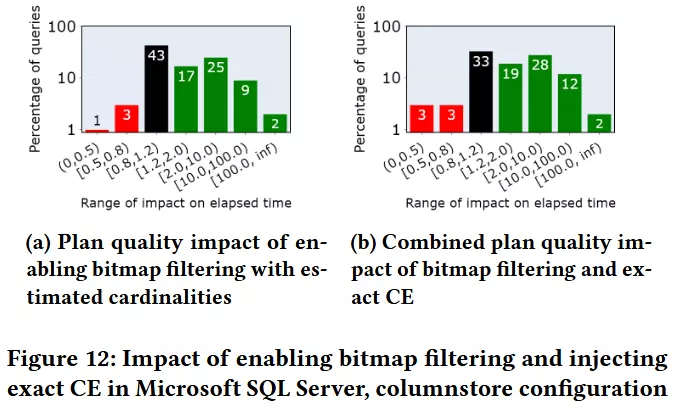
For this experiment, we use columnstores since bitmap filtering is used more extensively in columnstores when compared to rowstore.
原来如此,BitMap Filtering只在列存中用
从图中来看,效果还行?
6.2 Adaptive join
When using only exact cardinalities (see Figure 1(a)) 13% of the queries improve by 2× or more. In contrast, when using only adaptive join (see Figure 13(a)), we find only a few queries (less than 1%) that improve by 2× or more.

We find several reasons why adaptive join is unable to mask the impact of inaccurate CE, e.g., change in join order, change in physical operator, aggregation push-down (as noted in Section 4.2).
Such changes that lead to plan improvements are not achievable using adaptive join alone.
似乎效果达不到预期?因为其无法改变 Join 顺序、物理算子、或开启聚合下推(aggregation pushdown)等更根本的计划结构——说白了还是需要准确的CE
6.3 Other techniques and combinations
其实也没别的,就是并行对于计划的影响
In our study, for many queries, the optimizer uses parallelism only after exact cardinality injection.
Query Optimize对于并行的优化一直是个难题
RELATED WORK
主要是关于数据集的介绍
the Join Order Benchmark (JOB) using hand-crafted queries over the IMDB database.
CEB [38] provides additional queries over the IMDB schema
STATS [28], uses a real-world dataset similar to JOB, a snapshot of Stats Stack Exchange data
评论
好像有通过神经网络进行Cardinality Estimate的方案(Andy说他会在后面的课提到,但Andy的课4月份后就停更了)
一开始提到有Adaptive Join,我还是蛮期待的(和我目前做的方向有关),但看到不能调换Join顺序时就没兴趣了——怎么说,Cardinality Estimate是很重要,你说这不是废话吧,但大家确实对此没有定量分析的认知。
同样,CMU-15799的Lecture #14也是围绕这篇论文展开,感兴趣的可以去看看
